News Analysis: Big Tech Shows Signs Of Stability
News Analysis: Big Tech Shows Signs Of Stability


R “Ray” Wang is the CEO of Silicon Valley-based Constellation Research Inc. He co-hosts DisrupTV, a weekly enterprise tech and leadership webcast that averages 50,000 views per episode and blogs at www.raywang.org. His ground-breaking best-selling book on digital transformation, Disrupting Digital Business, was published by Harvard Business Review Press in 2015. Ray's new book about Digital Giants and the future of business, titled, Everybody Wants to Rule The World was released in July 2021. Wang is well-quoted and frequently interviewed by media outlets such as the Wall Street Journal, Fox Business, CNBC, Yahoo Finance, Cheddar, and Bloomberg. Short Bio R “Ray” Wang (pronounced WAHNG) is the Founder, Chairman, and Principal Analyst of Silicon Valley-based Constellation Research Inc. He…...
Read moreThe Q1 Tech Earnings Breathe Life Among The Digital Giants
With just Apple left to report in the tech earnings season, three major trends have emerged
- Digital Ad Winter Is Thawing. Alphabet, Meta, and Amazon are the big 3 in digital ads. Alphabet showed declines in ad revenue but posted $69.79B a 3% YoY increase and $1B above what analysts were expecting. YouTube dropped 2.5% YoY in ad revenue but paid subscription sales showed a 9% increase., Meta surprised the market with a 3% increase in the ad business hitting $28.6B for the first quarter. This reversed its trend of three quarters of decline. Meanwhile the 3rd largest player, Amazon showed continued growth in ads with a 27% growth rate at $31 billion.
The winners in ad monetization not only have the eyeballs but also are the dominant player in each business model. Google - search, Meta - social networks, and Amazon - commerce are showing that they are fierce competitors for digital advertising.
- Cloud Revenues Slow Down But Are Not Insignificant. Cloud adoption continues to power growth for Microsoft, Alphabet, but not Amazon. While the growth is slowing, double digit gains are nothing to sneeze at. Google Cloud gave Alphabet profits with 28% growth at $5.82 billion and finally was break even after 15 years. Microsoft showed 22% growth in cloud revenues. Amazon's more mature clientele shows that the market is about to enter an era of cloud optimization which means cloud revenues could take a hit. Amazon’s AWS showed this with a 16% cloud growth rate.
The era of cloud optimization is coming. Customers are starting to refactor workloads to optimize for data ingress and egress charges. Expect more rationalization in the next few quarters.
- AI Story Drives Valuations - A Tale Of Two AI Stories
The war for AI mind share in a post ChatGPT world is what’s driving tech valuations higher. While Microsoft kick started a war with Google earlier this year with Satya Nadella, MIcrosoft's CEO telling partners in Q1 that he would "bury" Google. Though Microsoft took the fight to Google in public, the reality is that Microsoft may not win the war as its servers are the oldest and it’s not taking a responsible approach to AI. The exponential amount of disinformation and misinformation will create massive cost to customers and society without the proper controls.
Meanwhile, Google has the best team, the best tech, but has been too slow to roll out offerings due to its bulkanized organizational structure and internal incentive system. Unlike Microsoft's command and control structure, collaboration is nearly impossible at a very federated Google. Google believes that creating a new "division" may help expedite innovation. However, Google must move faster, despite the realization that trust is important for AI adoption.
The Bottom Line: Tech Is Alive And Well Despite The Fed
The major tech players known as MATANA (i.e. MIcrosoft/Meta, Apple, Tesla, Alphabet, Nvidia, and Amazon) have shown much resilience despite interest rate hikes, massive cuts in valuations, a reset in earnings forecasts, and layoffs. MATANA stocks are poised for a rebound but will they move past their trading ranges in Q2? All eyes on the Fed Rate discussion this week and Apple's earnings to see what's next.
Your POV
Do you think the tech onslaught is over? Will the digital giants pull the market out of this self-inflicted crisis caused by The Fed.
Add your comments to the blog or reach me via email: R (at) ConstellationR (dot) com or R (at) SoftwareInsider (dot) org. Please let us know if you need help with your strategy efforts. Here’s how we can assist:
- Developing your AI, digital business, and experience strategy
- Connecting with other pioneers
- Sharing best practices
- Vendor selection
- Implementation partner selection
- Providing contract negotiations and software licensing support
- Demystifying software licensing
Reprints can be purchased through Constellation Research, Inc. To request official reprints in PDF format, please contact Sales.
Disclosures
Although we work closely with many mega software vendors, we want you to trust us. For the full disclosure policy,stay tuned for the full client list on the Constellation Research website. * Not responsible for any factual errors or omissions. However, happy to correct any errors upon email receipt.
Constellation Research recommends that readers consult a stock professional for their investment guidance. Investors should understand the potential conflicts of interest analysts might face. Constellation does not underwrite or own the securities of the companies the analysts cover. Analysts themselves sometimes own stocks in the companies they cover—either directly or indirectly, such as through employee stock-purchase pools in which they and their colleagues participate. As a general matter, investors should not rely solely on an analyst’s recommendation when deciding whether to buy, hold, or sell a stock. Instead, they should also do their own research—such as reading the prospectus for new companies or for public companies, the quarterly and annual reports filed with the SEC—to confirm whether a particular investment is appropriate for them in light of their individual financial circumstances.
Copyright © 2001 – 2023 R Wang and Insider Associates, LLC All rights reserved.
Contact the Sales team to purchase this report on a a la carte basis or join the Constellation Executive Network



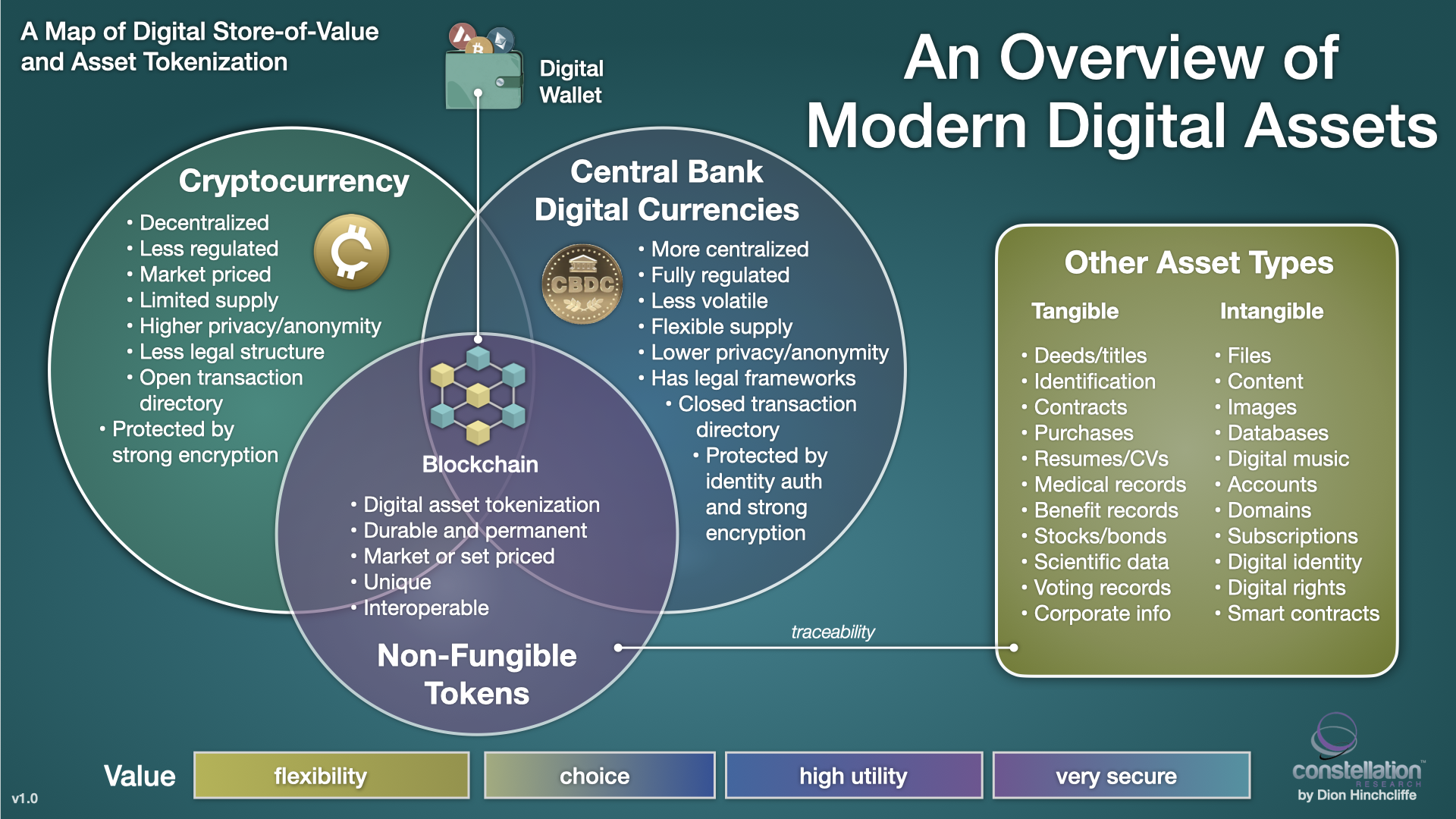






 In early 2023 I joined a rogue gaggle of industry analysts to trek to Zoho’s campus just outside of Chennai for an event dubbed Truly Zoho. Panel after panel of Zoho leaders shared an insider’s view and we analysts tried to accurately and fairly describe what we were hearing, seeing and experiencing. I’ve read article after article beautifully sharing the experience…but for some reason I was struggling. It wasn’t because there wasn’t plenty to share. I was struggling to document things in a way that was fair, accurate and, well, truly about Zoho.
In early 2023 I joined a rogue gaggle of industry analysts to trek to Zoho’s campus just outside of Chennai for an event dubbed Truly Zoho. Panel after panel of Zoho leaders shared an insider’s view and we analysts tried to accurately and fairly describe what we were hearing, seeing and experiencing. I’ve read article after article beautifully sharing the experience…but for some reason I was struggling. It wasn’t because there wasn’t plenty to share. I was struggling to document things in a way that was fair, accurate and, well, truly about Zoho. and core to the business value of every product and offering. When opportunities and a lack of R&D is holding a country back, what next? You invest in rural revival to bring globally in-demand skills and innovation to India despite the assumptions of the world that innovation only happens in places like the Silicon Valley.
and core to the business value of every product and offering. When opportunities and a lack of R&D is holding a country back, what next? You invest in rural revival to bring globally in-demand skills and innovation to India despite the assumptions of the world that innovation only happens in places like the Silicon Valley. One early and lasting experiment: finding a new way to identify, educate and train the next generation of experimenters. For 17 years, Zoho Schools of Learning (informally called Zoho University by some,) has seen over 1,400 graduates advance across technology, design and business. Built as an alternative to traditional college or university programs that can often exclude students from far-flung rural villages across India, Zoho Schools focuses on the often-overlooked student that may not have the means to attend University but has the curiosity and will to learn and experiment.
One early and lasting experiment: finding a new way to identify, educate and train the next generation of experimenters. For 17 years, Zoho Schools of Learning (informally called Zoho University by some,) has seen over 1,400 graduates advance across technology, design and business. Built as an alternative to traditional college or university programs that can often exclude students from far-flung rural villages across India, Zoho Schools focuses on the often-overlooked student that may not have the means to attend University but has the curiosity and will to learn and experiment.
 Sacrifice profit??? Zoho’s leaders decided to sacrifice growth to make a bold promise: nobody would be laid off as the world grappled with the threat of global financial recession and decline. For months we have seen headline after headline announcing layoffs. In order to appease Wall Street, investors, backers or shareholders, companies have made tough decisions to lay people off, cut back on research investments and implement austerity measures to keep ledgers in the black and ensure growth percentages did not fall. Zoho decided that the growth velocity they had consistently enjoyed over several years could slow if people could be prioritized.
Sacrifice profit??? Zoho’s leaders decided to sacrifice growth to make a bold promise: nobody would be laid off as the world grappled with the threat of global financial recession and decline. For months we have seen headline after headline announcing layoffs. In order to appease Wall Street, investors, backers or shareholders, companies have made tough decisions to lay people off, cut back on research investments and implement austerity measures to keep ledgers in the black and ensure growth percentages did not fall. Zoho decided that the growth velocity they had consistently enjoyed over several years could slow if people could be prioritized.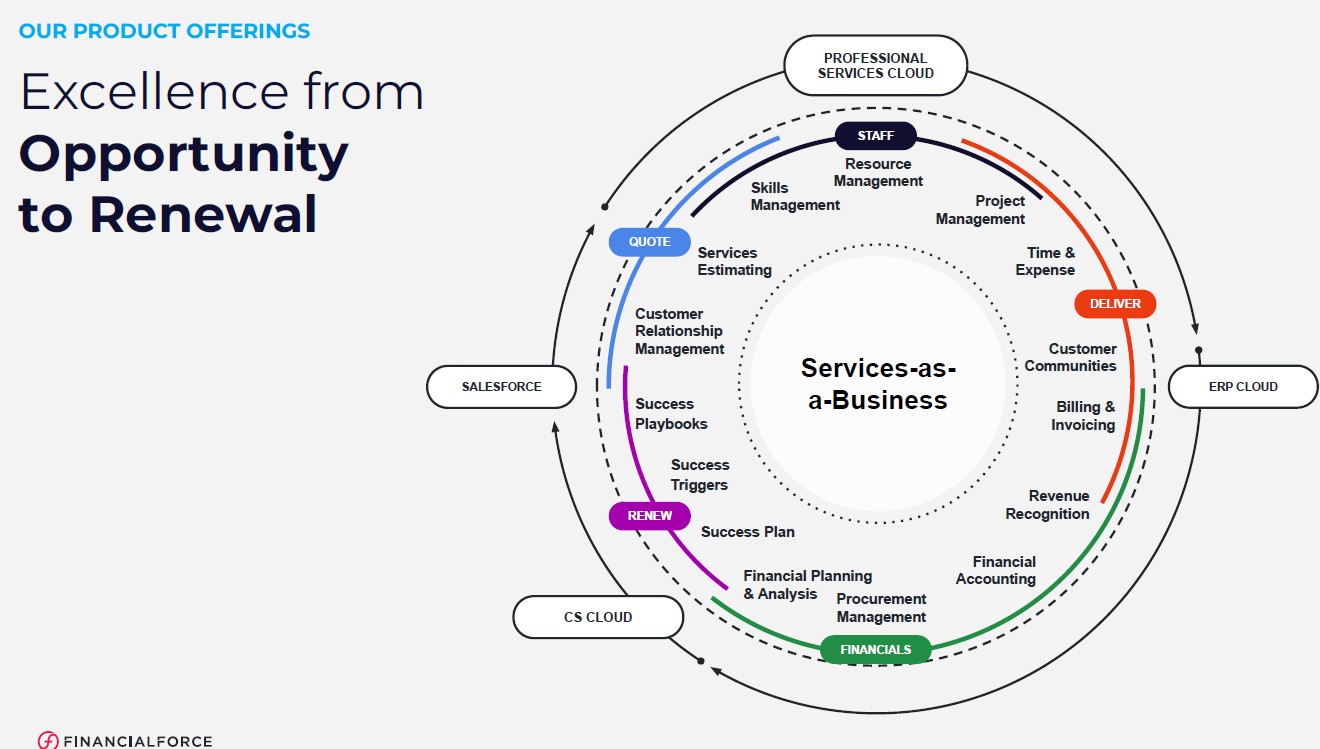



{kind=link}