How Leading Digital Workplace Vendors Are Enabling Hybrid Work
Vice President and Principal Analyst
Constellation Research
Title: About Dion Hinchcliffe
Dion Hinchcliffe is an internationally recognized business strategist, bestselling author, enterprise architect, industry analyst, and noted keynote speaker. He is widely regarded as one of the most influential figures in digital strategy, the future of work, and enterprise IT. He works with the leadership teams of large enterprises as well as software vendors to raise the bar for the art-of-the-possible in their digital capabilities.
He is currently Vice President and Principal Analyst at Constellation Research. Dion is also currently an executive fellow at the Tuck School of Business Center for Digital Strategies. He is a globally recognized industry expert on the topics of digital transformation, digital workplace, enterprise collaboration, API…...
Read more
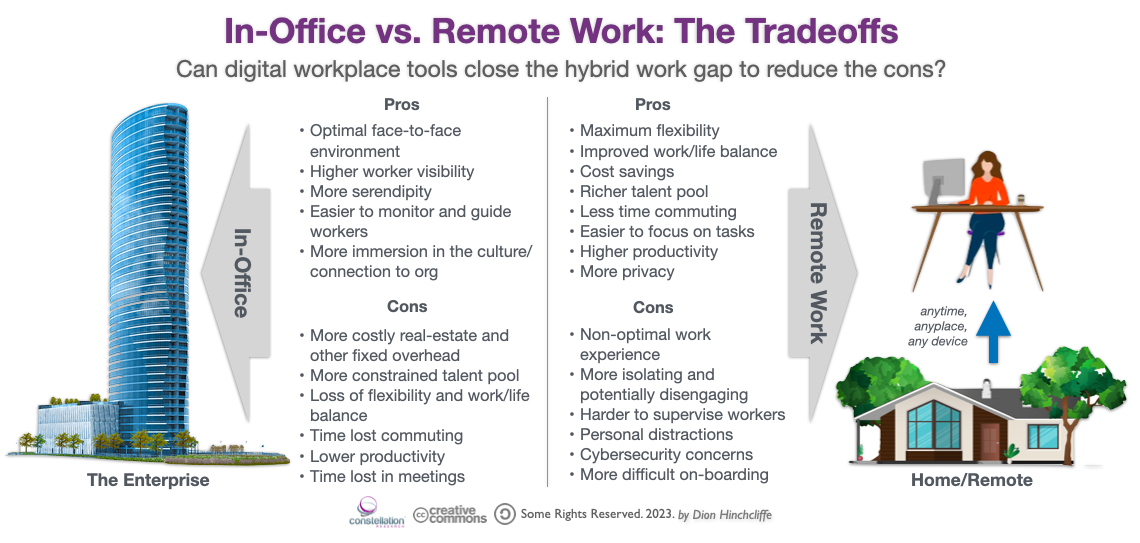
The phenomenon of hybrid work is now well upon us in 2023, as the world shifts into broad new patterns for how workforces are divided between office and remote. Roughly speaking, workers went from a high of about 46% remote during the pandemic, down to about a quarter of workers today and still falling a bit according to my research. This was from a small cohort of approximately 5% of workers who were remote before it became a major global phenomenon. Now workers -- especially in knowledge intensive businesses -- have become distributed between two primary locations: In-office or at a remote location, the latter typically their residence or a co-working space.
Now one of the leading questions about digital employee experience has become how to best enable this hybrid work environment. Business leaders, executives, digital workplace/employee experience teams, human resources, and other stakeholders are now realizing that this is a fundamentally new posture for our workplaces. Indeed, for many workers, all they really have now is a virtual workspace, not a specific physical place. What then are the vital adjustments to the design of the employee experience that must be made? What is the best route to achieve them, given that a growing percentage of work is done entirely in the digital realm in any case. Also, as we'll see, there are real challenges in having such a physically divided workforce.
The Steady Shift to Hybrid Work
The shift to mass remote work in early 2020 required a set of fundamental shifts towards a more digital overall employee experience, but one that few organizations were properly prepared for. This included everything from enabling basic access to devices and networks for everyone in the organization, then on to comms/collaboration, applications, data, along with (hopefully) matching new digital skills, all in a workable, secure package. This shift was a prompt imperative as the pandemic sent workers home en masse, and happened quickly and successfully in most organizations.

However, the subsequent shift to hybrid work is characterized by less urgency than the move to remote work was. And it's qualitatively different than remote work. As a result there are some significant challenges with hybrid work for which there are still few clear answers. This more gradual move is rather unlike what was largely the instant need for a remote work foundation (though the more advanced aspects of remote work are certainly still works in progress.) So the hybrid model will likely not get nearly as much attention or priority. Yet the challenges with hybrid work are in fact vital ones that go directly to what matters most to organizations: Attracting and retaining talent, fostering a strong and positively differentiating organizational culture, and not losing the distinct productivity dividend that emerged in many sectors during remote work, boosted by both automation and less time commuting.
Designing for Hybrid Work
With the ever growing jumble of apps and digital tools put in front of workers, the research increasingly shows that today's sophisticated workspaces now require organizations to put genuine investment and effort into coherently designing their digital employee experiences and digital workplaces, especially in the core journey, in order to have an effective and efficiently operating organization. As a result, a designed digital workplace is a key practice that I've been increasingly advocating in my research, advisory, and consulting work in developing next-generation workplaces, with gratifying results for those that have done this well.
My research currently shows that organizations are seeking to put a growing amount of effort into designing their core worker experience upfront in order to:
- Reduce onboarding time, effort, and cost
- Make new workers more effective on the job earlier
- Reduce complexity and friction in the most common/important processes
- Make existing and new work processes more effective
- Create more personalized and purposeful workspaces
However, achieving these goals requires that we have platforms and tools that are actually designed for the unique aspects of hybrid work. But up until recently that has not been the case, as the majority of the applications that organizations have used were instead designed for an earlier, mostly in-office era. Using these older solutions in a hybrid work environment as-is can become problematic, because of the unique aspects inherent to hybrid workplaces. This aspects are those characterized by having two separate cohorts of workers that are either in the office much of the time or workers that are remote much of the time, but have many tangible and intangible barriers between them. Fortunately, few digital work vendors have stood still and we are now seeing many of them seriously attempting to address the needs of hybrid workplaces.
Reducing the Challenges of Hybrid Work
Without explicit design for the significant and unique issues of hybrid work, the result is a digital work experience that inevitably perpetuates -- or actually creates -- a number of key issues that are essential to address for an effective, inclusive, and equitable hybrid workplace. These issues and challenges include:
- Cultural divide between in-office and remote workers
- Communications/collaboration gaps
- Productivity hits to hybrid teams
- Differences in equity and inclusion
- Disparities in visibility, transparency, and access
To that end, I've surveyed what the top providers of digital workplace tools have done to address the requirement of hybrid work. Since it is still early days in the hybrid work journey, many of these are experiments or educated guesses on what will address the issues. So it's safe to say that many providers are making a good effort to improve the state of the art in hybrid work, but the true effectiveness of these features aren't well understood yet. I will share what I learn as the results of these vendor experiments come in.
How Digital Workplace Vendors Are Supporting Hybrid Work
Below is a summary of the main improvements and additions that the most common used providers have made. I've emphasized communication, collaboration, and productivity tools since they are used a large percentage of the day and directly cross the intersection of the two main cohorts of hybrid work. The list below is sorted in rough order of the scale of efforts and general marketshare, to reflect the likely impact to the number of hybrid workers in the population.

Microsoft has been one of the leaders when it comes to providing specialized capabilities or updated features for hybrid work. Here is a non-exhaustive list of the notable additions to Microsoft365, Office365, and the company's other tools/platforms for hybrid work:
- RSVP for Outlook. Finding a good way to meet together a leading challenge for hybrid workers. Outlook now enables workers to indicate whether they will attend a meeting in-person or remotely. This helps workers plan better the days they will be in the office or remote, by seeing how others will attend meetings that are important to the worker.
- Hybrid-Enabled Working Hours. Outlook will now allow users to include work schedule specifics directly in a worker's calendar, so colleagues can find out when and where they'll be working. Key to bringing parity and inclusion to remote workers, who tend to have more flexible work hours and locations.
- Teams Rooms with Front Row. With this hybrid work feature, the video gallery appears at the bottom of the screen so in-room participants can see remote colleagues in a way that feels more face-to-face, so that they seem like they are in the same room.
- AI-Enhanced Video Presence. Microsoft is in the process of enabling a variety of smart video streams that focus on people and make them visually more present, especially for remote workers. The new category of AI-enabled cameras makes this possible, best embodied right now in a growing number of features for Microsoft Teams. There are three key technologies that deliver this new category of intelligent video presence: a) Active speaker tracking, which uses smart technology in in-room cameras to tap into audio, facial movements and gestures to detect who in the room is speaking, then dynamically zooming in for a closer view. b) Multiple video streams that enable in-room meeting participants to be positioned visually in their own video pane. c) People recognition, which will automatically identify and then display the profile name of users within the current video pane, if they have previously opted in.
- Video Presence in Powerpoint. Last year Microsoft introduced cameo, a new PowerPoint features that integrates the Teams camera feed into a presentation to allow the presenter to customize how, when, and where they'd like to appear in the presentation deck with their slides. This increases the presence of remote workers when the presentation is played back.
- Voice coaching in Teams. To help workers off all kinds collaborate better across the hybrid divide, there is a new AI-powered speaker coach in Microsoft Teams that privately shares tips and guidance on pace, any tendencies to interrupt others and remind workers to check in with your audience as they talk.
- A new end-to-end hotdesking experience. To help remote workers and more occasional in-office workers visit in-person, Microsoft now offers a more dynamic hotdesking experience right within Microsoft Teams displays that enables workers to locate and reserve flexible, on-demand workspaces in the office. Workers can book a physical working space within the device or before-hand using either Outlook or Teams. They can then access their personal Teams calendar, chats, meetings and more right on the device. Teams displays are designed be used as a stand-alone device or as a second screen while hot desking. After an employee signs out, all personally identifying information will be removed from the device.
- LinkedIn support for hybrid work information. LinkedIn has added new fields in job postings so organizations can now indicate if the open job is remote, hybrid or in-office only. This helps job seekers seek out and discover jobs that align with how they prefer to work. LinkedIn also has way for organizations to share how they are approaching work presence on their company page including vaccination requirements, and their current status on remote or hybrid work.
Sources: Great expectations: A road map for making hybrid work work, Microsoft and LinkedIn share latest data and innovation for hybrid work

For its part, Google Workspace has add a variety of features for hybrid work as well. These include:
- Virtual meeting onramps. Google has added a quick button to met directly in Docs, Sheets, and Slides. Workers are able to quickly start a meeting and bring the meeting session to a document, spreadsheet, or presentation. They can present this content to all the meeting attendees. This enables everyone in a meeting to collaborate in real-time while having a conversation, right from the same tab. This helps make it easier for remote workers to achieve better parity with in-office workers, who can more easily call physical meetings on the fly.
- Setting current work location. Like Microsoft has provided in Outlook, workers can now set their location for the work day right in Google Calendar. The feature is designed to allow meeting organizers as well as on-site teams to plan for the right mix of in-person and remote attendance. This feature also provides greater visibility and can help set expectations across hybrid teams.
- Companion mode for Meet. In-room meeting attendees now have a way to be more engaged with their personal devices while using in-room audio and video to improve the in-room experience. Google has started rolling out features for people in conference rooms to be able to add their own personal video tile from Companion mode using their laptop camera. This it easier for other attendees to see their expressions and gestures and connect better across the hybrid work divide.
- Connect hybrid teams with Spaces. Formerly known as Rooms in Google Chat), Spaces are a central virtual location for teams to collaborate in Google Workspace. Spaces brings in many of the Workspace tools like Meet, Calendar, Drive, Docs, Sheets, Slides and Tasks so that a living workspace can be created that's friendly for every time of worker, and persists after a collaboration session or planning meeting takes place.
Sources: Boosting communication and collaboration for teams of all sizes in Google Workspace, Make the most of hybrid work with Google Workspace, Bridging the hybrid work gaps with Google Workspace

From my ShortList of Employee Digital Workspaces of the same name, which are collaboration hubs designed for workers to get much of their work done in a team settling, here are the recent hybrid work features from some of the digital workplace providers on the list:
- Dropbox Spaces. While eschewing the term hybrid work, and preferring to talk instead about distributed work, the company's Spaces product was introduced just before the pandemic started (I was in attendance at the announcement.) As company, Dropbox now has a well-known policy of Virtual First, and uses its own products to enable hybrid work. As it turned out, Spaces was prescient in the need to create more context between in-office and remote workers. Spaces is designed to centralize and provide more context around content related to structured work like projects, no matter where workers are located. Spaces enables hybrid work by centralizing information and collaboration, and removes friction from the process of work (by storing comments instead of popping up endless notifications, for example), regardless of physical location. The latest version of Spaces is optimized for remote working, and has features that lets workers manage top priority tasks, even across multiple projects. Always one of my favorite features, Spaces includes integration with key 3rd party systems and tools like Hubspot. Sources: How to manage distributed work with Dropbox Spaces, The new Dropbox Spaces makes remote work easier and more organized
- Happeo. A social intranet designed around Google Workspace that has steadily climb the rankings over the years, Happeo offers a wide range of collaboration features that are appealing for both remote and in-office workers. Perhaps most important is creating a hybrid culture, as Happeo is designed to help remote workers feel like they are a part of the organization by keeping them informed about happenings from around the company. Happeo has an unusually deep analytics tool to help companies understand hybrid work engagement patterns and address shortfalls. It also specifically has high security standards for remote work, which has been a notable issue for remote workers. Happeo has a highly customizable mobile app which lets hybrid workers build the views they need to stay connected to the company. Source: Happeo's Remote Work Software
- HCL Connections. Long an industry stalwart, Connections remains one of the pre-eminent social workspaces in the industry. The recent v7 release of Connections added dynamic community creation wizard that helps hybrid teams more quickly create the groups they need to span in-office and remote workers. New Microsoft365 integration further helps break down silos between distributed teams. Source: HCL Connections v7 Is Here
- Igloo Software. The company has a networked enterprises feature that allows the creation of nuanced hybrid teams based on the audience type. Using a hub and spoke architecture, enterprise administrators can bring in different groups, divisions, geographies, and affiliates while deferring some local control to site administrators. Developed before the pandemic, the feature is particular powerful today, as companies build distributed organizations with far flung boundaries and borders. Source: Networked Enterprises
- Lumapps. A digital workspace solution that has won top intranet awards, Lumapps is not as well known as some of the solutions here but has been delivering a distinguished offering for some years now, and I run into it more often in clients that I used to. The platform offers features that help remote/distributed workers (in addition to in-office ones), including a digital headquarters to allow workers to access files and information and stay connected with each other. Features to foster belonging, including virtual onboarding, training, and employee generated content, are offered as well. These features are used by well known highly distributed/remote companies like Thoughtworks. Source: A Platform for Remote and Hybrid Work
- Salesforce. The well-known SaaS giant created their Success from Anywhere program, through which it has learned what large global organizations must do to empower hybrid and remote teams and rolled what they learned from the program into their products.
What Actually Works to Enable Hybrid Work
As you review these various new features and capabilities for hybrid work above, and you come to the conclusion that many are point features that are not highly strategic, you would not necessarily be wrong. The reality is that we are still learning what organizations really need when it comes to hybrid work. 2023 is a year of mass experimentation for how organizations will try to better enable hybrid work, not just with technology, but with process and education as well. In particular education about the capabilities above will be central to shifting behavior so that hybrid teams work more optimally. We now live in a time where how-to videos, just-in-time training, and digital adoption platforms can help workers rapidly pick up the new mix of skills and techniques that these hybrid work features enable.
To that end, I've embarked on a major research study to learn what organizations are actually doing this year with hybrid work, including what is working and not working. If you're responsible for some aspect of realizing hybrid work at your organization and would like to participate (and get early access to the data), please send me a note.
Also, if you are a digital workplace tool provider and would like your hybrid work features added to the list above, also drop me a line.
My Additional Research on the Future of Work
Every Worker is a Digital Artisan of Their Career Now
How to Think About and Prepare for Hybrid Work
Why Community Belongs at the Center of Today’s Remote Work Strategies
Reimagining the Post-Pandemic Employee Experience
It’s Time to Think About the Post-2020 Employee Experience
Research Report: Building a Next-Generation Employee Experience: 2021 and Beyond
The Crisis-Accelerated Digital Revolution of Work
Revisiting How to Cultivate Connected Organizations in an Age of Coronavirus
How Work Will Evolve in a Digital Post-Pandemic Society
A Checklist for a Modern Core Digital Workplace and/or Intranet
Creating the Modern Digital Workplace and Employee Experience
The Challenging State of Employee Experience and Digital Workplace Today
The Most Vital Hybrid Work Management Skill: Network Leadership
New C-Suite
Future of Work
Tech Optimization
Data to Decisions
Innovation & Product-led Growth
Marketing Transformation
Next-Generation Customer Experience
Digital Safety, Privacy & Cybersecurity
Chief Experience Officer