AWS re:Invent 2023: Perspectives for the CIO | Live Blog
I'm excited to be live from AWS re:Invent 2023 in Las Vegas This year's event is packed with announcements about the leading-edge of cloud computing and the hot topic of the year, generative AI. It's also rife with opportunities for cloud professionals to learn and grow. From a CIO perspective, I'm particularly interested in the keynotes, innovation talks, and builder labs to show where the AWS as a platform is heading for IT leaders. I'm also looking forward to networking with CIOs and cloud experts from around the world to compare notes.
Jump right to the Live Blog
As arguably the cloud industy's pre-eminent event, I'm eager to explore the following topics at re:Invent this week, which I believe are the most vital to examine in our enterprise journey through cloud today:
1. Cloud Economics and Cost Optimization
With rising economic pressures, CIOs are increasingly focused on optimizing cloud costs without compromising performance or agility. AWS re:Invent 2023 is expected to showcase new "tools and strategies for managing cloud expenditures, including cloud cost management tools, FinOps frameworks, and cost optimization techniques.
2. Embracing Hybrid, Private, and Multi-Cloud Environments
Organizations are increasingly adopting hybrid and multi-cloud strategies to leverage the best of each cloud provider and ensure resilience. AWS re:Invent 2023 will explore advancements in hybrid cloud management, including solutions for managing multi-cloud environments, data portability, and application deployment across different cloud platforms including private cloud, the resurgence of which is one of my major research areas currently.
3. Accelerating Innovation with AI and Machine Learning
AI and machine learning (ML) are transforming businesses across industries. CIOs are eager to harness the power of these technologies to drive innovation and gain a competitive edge. AWS re:Invent 2023 will delve into the latest AI and ML services, including tools for building AI models, deploying ML applications, and automating IT operations with ML.
4. Enhancing Cybersecurity and Data Protection
Cybersecurity threats are becoming more sophisticated, and CIOs must prioritize protecting sensitive data and ensuring compliance. AWS re:Invent 2023 will feature sessions on cloud security best practices, identity and access management, data encryption, and threat detection and response.
5. Building and Managing Sustainable Cloud Infrastructures
Sustainability is becoming a critical factor for organizations, and CIOs are seeking ways to reduce their cloud footprint's environmental impact. AWS re:Invent 2023 will highlight cloud-based sustainability solutions, including carbon footprint tracking tools, energy optimization techniques, and green data center initiatives.
6. Empowering Developers with Cloud-Native Technologies
Developers are the backbone of cloud innovation, and CIOs must provide them with the tools and resources they need to succeed. AWS re:Invent 2023 will showcase cloud-native technologies, including containerization, serverless computing, and API management solutions, to empower developers to build and deploy applications rapidly and efficiently.
7. Fostering a Culture of Cloud Agility and Innovation
Cloud adoption is not just about technology; it's also about fostering a culture of agility and innovation within the organization. AWS re:Invent 2023 will explore strategies for driving organizational change, empowering employees to embrace cloud technologies, and creating a culture of continuous learning and experimentation.
8. Leveraging Cloud for Industry-Specific Solutions
Cloud adoption is transforming industries across the board. AWS re:Invent 2023 will feature sessions tailored to specific industries, showcasing how cloud solutions are being used to address unique challenges and opportunities in healthcare, finance, manufacturing, retail, and other sectors. This is a key reason I find that the hyperscalars are key platorms for digital transformation, if they have the blueprints and templates for bringing the cloud directly into how businesses work.
9. Exploring the Future of Cloud Computing
As cloud computing continues to evolve, CIOs are looking to the future for insights into emerging trends and technologies. AWS re:Invent 2023 will provide a glimpse into the future of cloud computing, with sessions on quantum computing, edge computing, and the next generation of cloud infrastructure.
AWS re:Invent 2023 Live Blog
First up is the Monday evening keynote with Peter DeSantis at 7:30pm PT. Peter is Senior Vice President of AWS Utility Computing. He will discusses how AWS is pushing the envelope of what’s possible. He will describe the engineering that powers AWS services and illustrates how their unique approach and approach to innovation helps create leading-edge solutions across the spectrum of silicon, networking, storage, and compute, with the goal of uncompromising performance and cost.

7:30pm PT: Peter DeSantis comes on stage and begins to make a sophisticated argument for highly scalable cloud computing and serverless.
7:40pm PT: "You can get serverless scaling of your database storage because your database has access to robust distributed storage service [in tthe cloud] that can scale seamlessly and efficiently as a single table from massive database. And when the database gets smaller, that's taken care of to drop a large index to stop paying for the index. That's how the service works. With our launch of Aurora, we took a big step forward on our journey to making the relational database less, more server less."
7:45pm PT: After walking through many scenarios of how to scale databases, DeSantis conclucdes that "we're still limited by the size of the physical server. And that's not serverless. However, database sharding is a well known technique for improving databases performance of a single server, given both horizontally partitioning your data into subsets and distributing it to a bunch of physically separate database servers called shards." Clearly, horizontal scaling is the answer, but how do it with the epic scale that today's multilmillion users systems require?

7:50pm PT: "We've changed the database to use Wallclock to create a distributed database that is very high performance. And it's made possible by a very novel approach to synchronizing. Syncing the clock sounds like it should be as simple as one server or another server timings. But of course, because the time it takes to send a message from one server to another server and without knowing this propagation time, it's impossible from this box by passing protocols to calcualte by sending round trip messages and subtracting tropical clouds." Peter builds up to a big announcement by tipping the breakthrough research required to achieve it.
7:55pm PT: Announces Amazon Aurora Limitless Database. "With a limitless database there's no need to worry about providing a new database, your application is just a single endpoint that has to be available." My take: This is a major reduction in complexity that will move the state-of-the-art in cloud data management forward.

8:30pm PT: Now Peter DeSantis takes us on a fascinating exploration of their efforts in quantum computing, including AWS's work on making it real. The basic issue is that qubits today are far too noisy to tackle serious computation issues. DeSantis takes through the story of logical qubits and the work AWS is doing to make them commercially viable. This tech looks five years out at least, but they are clearly gearing up because the tech will be critical to tackle issues in scientific research, cryptography, pharmacology, and other domains. Overall, an impressive look at where AWS will take enterprises into the frontier of computing, all delivered through public cloud of course.

Adam Selipsky Keynote | November 28th, 2023 at 8:00am
8:00am PT: Starting right on time, Adam comes out and makes the case that Amazon is the leading cloud platform in the world. "We are relentless about working backwards from our customers needs and from their pain points. And of course, we were the first by about five to seven years to have this broadest and deepest set of capabilities we still have and we're the most secure, the most reliable."

8:10am PT: Continuing the trend to showing love to the core AWS platform, Selipsky talks about S3, their original cloud storage service. "So, 17 years ago, AWS reinvented storage by launching the first cloud service for AWS with S3. As you can see as we continue to how development use store, same simple interface, low cost, and high performance. It's another example of general purpose computing. We realized almost 10 years ago, that we wanted to continue to push the envelope on price performance for all of your workloads, which are reinfect general purpose computing, for the cloud era, all the way down."
8:12am PT: The first big announcement of Day of re:Invent: "I'm excited to announce Amazon s3 Express was a new s3 storage class, purpose built. Purpose Built on a high performance and lowest latency Cloud Object Storage for your most frequently accessed data. Express One uses purpose built hardware and software to accelerate data processing also gives you the option to actually choose your performance for the first time. It can bring frequently accessed data next to your high performance compute resources to minimize latency." Express One supports millions of requests per minute with a claimed single digit millisecond latency with very fast object storage in the cloud. Selipsky says it is up to 10 times faster than S3 standard storage. While cloud costs continue to remain paramount with many IT departments, AWS is still focusing on overall performance as well, key to landing the largest online services.

8:15pm PT: Now Selipsky moves onto server compute, the workhorse of cloud platforms. Notes that 50,000 customers currently use their custom-designed Graviton chips today. "For example, SAP partners with AWS to power SAP HANA Cloud with the Graviton chip. SAP is seeing up to 35% better price performance for analytics workloads as it aims to reduce carbon footprints or carbon impact by an estimated 45%." This confirms the performance gains/cost savings of using chips optimized for cloud compute workloads.
8:17pm PT: Announces the Graviton4, "the most powerful and the most energy efficient chip that we have ever built. With 50% more cores and 75% more memory bandwidth the Graviton, with 30% faster on average than the Graviton3, performs even better for certain workloads, like 40% faster for database applications." Notes that AWS is on its fourth generation of cloud servier processors, and says their competitions is often not even on their first. There is a new Graviton4 preview that customers can join if they like.

8:20am PT: Now Selipsky gets into how AWS things about artificial intelligence. Specifically, they see it having three layers
Layer 1 - Infrastructure for training/inference
Layer 2 - Tools to build with LLMs
Layer 3 - Applications that leverage LLMs
8:22am PT: Next up is GPUs, the workhorse of AI. Selipsky notes that "having the best chips is great and necessary. But to deliver the next level of performance you need more than just the best GPU. You also need really high performance clusters of servers that are running these that can be deployed and easy to use ultra clusters." Next he talks about AWS differentiation with GPUs, namely: "All of our GPU instances that have been released in the last six years are based on our breakthrough Nitro system, which reinvented virtualization by offloading, storage and networking specialized chip to all the service compute dedicated for running your workloads. This is not something that other cloud providers can offer." My take: This lightweight hypervisor is key to AWS's cost/performance advantage for many advanced workloads, and scale them up to 20,000 GPUs at once, AWS claims.
8:23am PT: Brings Jensen Huang up on stage, co-founder and CEO of NVIDIA, who is certainly making the rounds at all the cloud events as the generative AI partner darling of the year, given their pre-eminence in the GPU industry, instrumental to training and running AI models. Their DGX platform has been a key differentiaor for them and has captured the leading marketshare in the industry.

8:28am PT: Huang makes a lot of interesting statements, mostly about scale, which is the signature challenge of generative AI. "We are incredibly excited to build the largest AI factory NVIDIA has ever built. We're going to announce inside our company we call it Project Siba(?). Siba, as you all probably know, is the largest, most magnificent tree in the Amazon. We call it project Siva. Siva is going to be 16,384 cores connected into one giant AI supercomputer. This is utterly incredible. We will be able to reduce the training time of the largest language models the next generation mo ease these large, extremely large mixture mixture of experts models, and be able to train it in just half the time. essentially reducing the cost of training in just one year and how now we're going to be able to train much much larger multimodal M models this next generation large language models." Another proof point that NVIDIA is at the forefront of helping build the largest AI models ever created.
8:35am PT: Now the new Tranium2 chip is announced. Designed to quickly and inexpensive training AI models. "This second generation system is purpose-built for high performance training. It was designed to deliver four times faster performance compared to our first generation chips that makes it ideal for training front foundation models with multiple hundreds of billions or even trillions of parameters." This will very much help sustain AWS's claims that their Tranium chips offer unique performance and cost effective aids for organizations making major forays into generative AI.

8:37am PT: Now Selipsky talks about the software frameworks on top of their custom ML and AI chips. "AWS Neuron is our software development kit that helps customers get maximum performance from our ML chips. Neuron supports our machine learning framework frameworks like TensorFlow so customers can use their existing knowledge both training and inference pipelines is just a few lines of code. Just as importantly, you also need the right tools to help train and deploy your models. And this is why we have Amazon Sagemaker. Our managed service makes it easy for developers to train to build machine learning and foundation balls. In the six years since the first Sagemaker, we've introduced many powerful innovations like automatic public tuning, a distributed training, flexible model deployment tools for ml ops and built in features like responsible AI." This vertical integration of hardware and software is a very compelling offering in the ML and AI spaces, and certainly we've seen Sagemaker climb the usage charts around the world since its release. Selipsky continually beats the drum today on public cloud being the most compelling price/performance for training. My verdict: It depends on the workload and how often is must be trained especially.

8:40am PT: Selipsky reaffirms AWS's stance on full model choice: "So you don't want a cloud provider who's beholden primarily to one model. You need to be trying out different models. You need to be able to switch between them randomly even combining them with the same use case. And you need a real choice model as you decide who's got the best technology, but also who has dependability that you need a business partner. I think the events of the past 10 days. We've been consistent about lead for choice for the whole history of AWS." So, after taking a swing at the turbulence at OpenAI, Selipsky then shows that they do have preference, just that they're open. Because of who is up next...
8:42am PT: Now the CEO of Anthropic, Dario Amodei, is invited up on stage with Selipsky. They talk about Claude 2. Talks about their desire to be the leader in safe, reliable, steerable Generative AI. Claude 2 can handle 200K tokens and is "10 times" more resistant to halllucinations that other opic models. My take: It looks like Anthropic is the AI model that's first among equals in AWS AI model choice.

9:03am: After some customers stories from Pfizer and others, Selipsky moves onto the vital enterprise topic of Responsible AI, something that AWS recenly reaffirmed its corporate commitment to. "We need generative AI to be deployed in a safe, trustworthy and responsible fashion. That's because the capabilities to make generative AI such a promising tool for innovation also have the potential to deceive. We must find ways to unlock generaive AI's full potential while mitigating the risks. Dealing with this challenge is going to require unprecedented collaboration through a multi-stakeholder effort across technology companies, policymakers, community groups, scientific communities, and academics.
We've been actively participating in a lot of the groups have come together to discuss these issues. We've also made a voluntary commitment to promoting safe, secure and transparent AI development technology [to build] applications that are safe, but avoid harmful outputs, and that stay within your company. And the easiest way to do this is actually placing limits on what information we can or can't return. We've been working very hard here and so today we're announcing Guardrails for Amazon bedrock."
This is maybe the most impactful announcement regarding AI at re:Invent so far. Making enterprise safe, transparent, and risk managed is one of the highest priorities for organizations as they develop generative AI policies -- see my roadmap for AI at work here -- and build applications for it.

9:16am PT: Now Selipsky talks about cloud talent, is vital subject and urgent situation holding back innovation and digitat transformation in many organizaitons today. He notes that that AWS plans to "provide the cloud skills that we are going to be needed across the world for years to come. AWS has committed to training 29 million people for free with cloud computing skills by the year 2025. We're well on our way to 21 million already."
9:18am PT: Selipsky moves the conversation onstage to "generative AI chat applications. So these days, what the early [generative AI] providers in the space have done is really exciting, and it's genuinely super useful for consumers. But a lot of ways these applications don't really work at work. With their general knowledge and their capabilities are great But they don't know your company. They don't know your data or your customers or your operations. And this limits how useful their suggestions can be.
They also don't know much about who you are at work. They don't know your all your preferences. What information you use, what you do and don't have access to. So critically other providers from the launch tools, they launched out their privacy and security capabilities that virtually every enterprise requires. So many CIOs actually banned the use of a lot of these [Dion: 22% of orgs in my most recent CIO survey] most popular AI systems inside their organization that has been well publicized. Just ask any Chief Information Security Officer CISO. They'll tell you the full time security fact and expect it to work as well much much better to build security, fundamental design technology."

9:20am PT: In what is probably the biggest enerprise AI announcement at re:Invent, Selipsky tips Amazon Q, a new enterprise-grade generative AI chat system, akin to ChatGPT, but designed businesses. Amazon Q is especially designed for enterprises to "understand your systems, your data repositories, your operations. And of course we know how important rock solid security privacy are that you understand respect your existing identities for roles in your permissions that the user does not have permission to access something without you they cannot access it with you either. We've designed to meet enterprise requirements. Enterprise customers have stringent requirements from day one." Says they will never use customer data in their models, ever, which will be absolutely key. Amazon Q is in preview today (see link above.)
The pricing page for Amazon Q puts a premium investment level on AWS's new business chat app service:
- $20/month per user for Q Business
- $25/month per user for Q Builder
My take: Given that finding information to carry out knowledge work is still one of the biggest unmet needs in the digital workplace, if Amazon Q can deliver the goods, it has the potential to be worth the price.

9:25am PT: Amazon Q is also an expert on the AWS platform, and can actively help developers and operations staff (DevOps teams) get far more from he platform. "Amazon Q is your expert assistant for building on AWS how to supercharge developers and IT pros. We've trained as on two and a half years worth of AWS knowledge. So I can transform the way you think, optimize and operate application workloads on AWS. And we put Amazon Q where you work, so it's ready to assist you in the AWS Management Console as your code whisperer and in your team chat apps like Slack, Amazon Q is an expert in AWS tech pattern and practices and solution implementations."
Swami Sivasubramanian Keynote | November 29th, 2023 at 8:30am
8:30am PT: Sivasubramanian comes out and talks about Ada Lovelace, and her conjecure that computers could only do what they're programmed to do, not come up with ideas that are enirely new. Suggests the AI era will change that. Then dives right into a discussion of the generative AI stack as AWS sees it:

8:41pm PT: Now Sivasubramanian gets to the most important topic perhaps of all: Model choice. He underscores the AWS position: "No one model will rule them all." Large language models and foundation models will come in many flavors for many needs. Indeed, our estimate is that most orgs will soon have dozens or even hundreds of them.

8:43am PT: Next, Sivasubramanian explores the specific foundation models (FMs) and large language models (LLMs) that Amazon Bedrock supports. Bedrock stands at the core of AWS's generative AI services in the cloud. AWS describes Bedrock as a "managed service that offers a choice of high-performing foundation models (FMs) via a single API." It supports FMs and LLMs from leading AI companies including AI21 Labs (Jurassic), Anthropic (Claude), Cohere (Command + Embed), Meta (Llama 2), Stability AI (Stable Diffusion), and Amazon (Titan).
My take: Model choice is one of the most important dimensions of generative AI to properly realize and enable. Cloud vendors are now in a race to provision and make safe as many FMs and LLMs as possible, with Google at the head of the pack, AWS catching up, and Microsoft betting heavily mostly on OpenAI. Choice is likely to win the day and will be a critical dimension to track over the next couple of years.

8:51am PT: Interestingly -- and continuing a trend throughout re:Invent -- gives special attention to Anthropic's Claude 2.1 LLM, citing key advantages like a comparatively large 200K token context window, 2x less model hallucination, and 25% lower cost of prompts/completions.

8:53am PT: Multimodal applications that use different types of daa are complex and hard to build says Sivasubramanian, correctly. "Developers need to spend time piecing together multiple models. Not only does this increase the complexity of your daily tasks, but it also decreases the efficiency and impacts customer experience. We wanted to make these applications even easier."
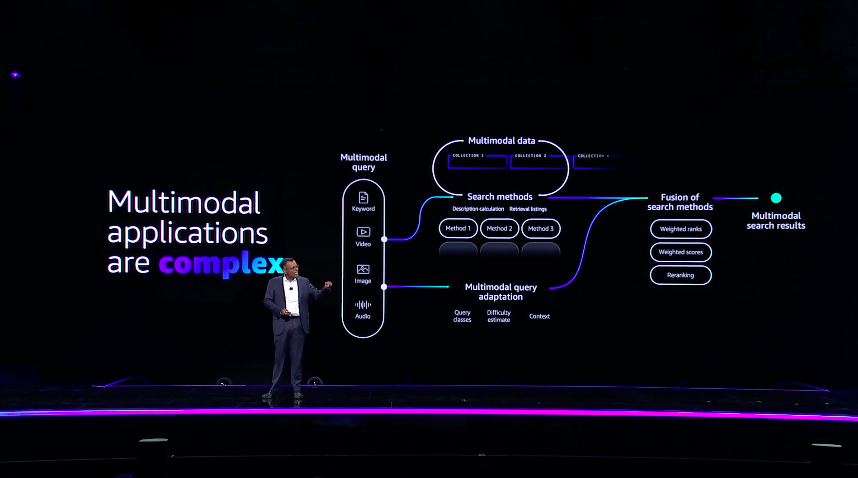
8:54am PT: "That's why today I'm excited to announce the general availability of Titan Multimodal Embeddings. This model enables you to create richer, multimodal search and recommendation options, we can quickly generate store and retrieve embeddings more accurately and contextually relevant, in one type of search. Companies like Opera are using pattern multimodal embeddings as well as inline which is using this morning to revolutionize this document search experience for their customers." A key feature is that it can adapt to unique and proprietary business data. And it has built-in bias reduction.

8:55am PT: Continuing a focus on price/performance in AI -- something key as FMs and LLMs can be very costly to run in daily opeations -- Sivasubramanian announces Titan Text Lite and Titan Text Express (see video demo here). "These next models help you optimize for accuracy, performance and cost depending on your use cases. These are really, really small models that are extremely cost effective model that supports use cases like text summarization. It is ideal for fine tuning, offering your highly customizable model for your use case. Express can be used for a wide range of tasks such as open ended text generation and conversational chat. These two models provides a sweet spot for cost and performance compared to other really big [foundation/large language] models."

8:56am PM: The new Amazon Titan Image Generator service is announced, now available in preview.
- Studio-quality images from natural language prompts
- Customize with enterprise data/brand
- High alignment of text to image

9:05am PT: After a deep-dive into how Intuit is using AWS's AI platforms, Sivasubramanian shifts the conversation to the absolute centrality of data to generative AI. The key here is that AWS is prepared to indemnify orgs against what's generated on their platform, including saying it will guard them against legal and reputational damage. They also promise enterprise data will never flow back into their models, but don't offer the same sort of indemnification.

9:07am PT: So, how can organizations "enable your model to understand your business over time." Sivasubramanian explains how fine-tuning is the process for customizing models with enterprise data. Titan supports both fine-tuning with labelled and unlabelled raw data, and is key to getting AI adapted to a business. Sivasubramanian re-emphasizes that fine-tuning always stays with the customer, and never flows back into AWS's base AI models.

9:09am PT: There are two major ways to customize AWS's Titan model to adapt to a given business:
- Small, labelled data -> Fine-tuning
- Large amount of unlabeled data -> Continued pre-training
These two approaches are key to making generative AI adapt to a business.
Sivasubramanian gives an example: "A healthcare company can pre-train the model that using medical journals, articles or research papers to make it more knowledgeable on the evolving industries are not. And you can leverage both of these techniques, to act on Titan Lite and Titan Express. These approaches complement each other and will enable your model to understand your business over time. But no matter which method you use, the output model is accessible only to you and it never goes back to the base model."

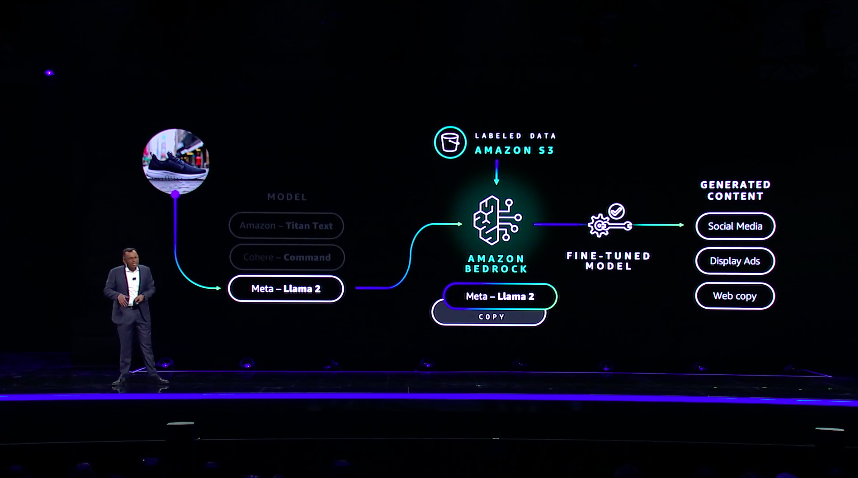
9:12am PT: Then Sivasubramanian takes us through an an example of how a generative AI model in Bedrock can be fine-tuned w/itha copy of Meta's Llama2 LLM. Then labelled enterprise data is added in via the S3 storage service. The resulting fine-tuned model is used to generate customized, business-relevant content as needed. This is one way to adapt a model in the AWS platform to a business. But it's not the only way, and may not be suitable for large amounts of data or when domain accuracy is strictly needed.
9:15am PT: But there are other ways to integrate enterprise data with an LLM, even than these two more strategic options. There is also an approach known as retrieval augmented generatation (RAG), which Sivasubramanian walks through as well, and is what many people already do by hand with LLMs today. Understanding these options in terms of pros/cons so that enterprises can evaluate how best to mix in their valuable data with an AI model's data. In the RAG approach "the prompt that is sent to your foundation model contains contextual information such as product details, which it draws from your private data sources. These are in the context within the prompt text itself. Hence the model provides more accurate and relevant response due to the use of specific prompt-supplied business details." This is a 3rd way, beyond fine-tuning and continued pre-training, to get an AI model to generate using business-specific private data.
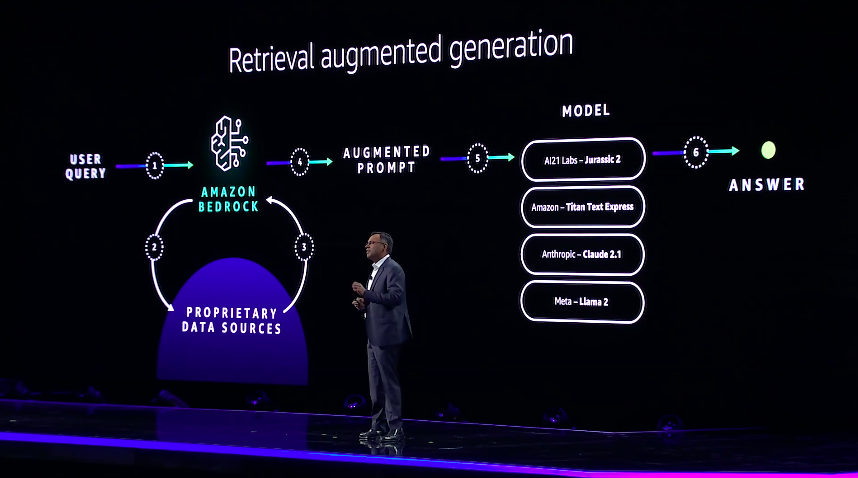
9:18am PT: The next announcement that Sivasubramanian makes is Knowledge Bases for Amazon Bedrock, which is an off-the-shelf way to implement the RAG workflow described above to give foundation models contextual information from an organization's private data sources. Specifically Knowledge Bases performs the following in a proven workflow:
- Converts text docs into embeddings (vector representations)
- Stores them in a vector database
- Retrieves them + augment prompts Avoids custom integrations.
Put simply, the service can look at Amazon S3 and then it automatically fetches the documents, divides them into blocks of text, converts the text into embeddings, and stores the embeddings in a vector database. Then this information can be retrireved and used in a variety of generative activities. Interestingly and very usefully, the service can provide source attribution if needed as well.

Related Research
My AWS re:Invent 2023 "mega thread" with all the ongoing details this week
A Roadmap to Generative AI at Work
Last year's AWS reInvent Live Blog for 2022
My current Digital Transformation Target Platforms ShortList
Private Cloud a Compelling Option for CIOs: Insights from New Research
The Future of Money: Digital Assets in the Cloud for Public Sector CIOs
Title: About Dion Hinchcliffe Dion Hinchcliffe is an internationally recognized business strategist, bestselling author, enterprise architect, industry analyst, and noted keynote speaker. He is widely regarded as one of the most influential figures in digital strategy, the future of work, and enterprise IT. He works with the leadership teams of large enterprises as well as software vendors to raise the bar for the art-of-the-possible in their digital capabilities. He is currently Vice President and Principal Analyst at Constellation Research. Dion is also currently an executive fellow at the Tuck School of Business Center for Digital Strategies. He is a globally recognized industry expert on the topics of digital transformation, digital workplace, enterprise collaboration, API…...
Read morePublished
Author
