Nvidia Accelerates Artificial Intelligence, Analytics with an Ecosystem Approach
Nvidia’s GTC 2018 event spotlights a play book that goes far beyond chips and servers. Get set for next era of training, inferencing and accelerated analytics.
“We're not a chip company; we're a computing architecture and software company.”
This proclamation, from NVIDIA co-founder, president and CEO Jensen Huang at the GPU Technology Conference (GTC), March 26-29 in San Jose, CA, only hints at this company’s growing impact on state-of-the-art computing. Nvidia’s physical products are accelerators (for third-party hardware) and the company’s own GPU-powered workstations and servers. But it’s the company’s GPU-optimized software that’s laying the groundwork for emerging applications such as autonomous vehicles, robotics and AI while redefining the state of the art in high-performance computing, medical imaging, product design, oil and gas exploration, logistics, and security and intelligence applications.

Jensen Huang, co-founder, president and CEO, Nvidia, presents the sweep of the
company's growing AI Platform at GTC 2018 in San Jose, Calif.
On Hardware
On the hardware front, the headlines from GTX built on the foundation of Nvidia’s graphical processing unit advances.
- The latest upgrade of Nvidia’s Tesla V100 GPU doubles memory to 32 gigabytes, improving its capacity for data-intensive applications such as training of deep-learning models.
- A new NVSwitch interconnect fabric enables up to 16 Tesla V100 GPUs to share memory and simultaneously communicate at 2.4 terabytes per second -- five times the bandwidth and performance of industry standard PCI switches, according to Huang. Coupled with the new, higher-memory V100 GPUs, the switch greatly scales up computational capacity for deep-learning models.
- The DGX-2, a new flagship server announced at GTC, combines 16 of the latest V100 GPUs and the new NVSwitch to deliver two petaflops of computational power. Set for release in the third quarter, it’s a single server geared to data science and deep-learning that can replace 15 racks of conventional CPU-based servers at far lower initial cost and operational expense, according to Nvidia.
If the “feeds and speeds” stats mean nothing to you, let’s put them into the context of real workloads. SAP tested the new V100 GPUs with its SAP Leonardo Brand Impact application, which delivers analytics about the presence and exposure time of brand logos within media to help marketers calculate returns on their sponsorship investments. With the doubling of memory to 32 gigabytes per GPU, SAP was able to use higher-definition images and a larger deep-learning model than previously used. The result was higher accuracy, with a 40 percent reduction in the average error rate yet with faster, near-real-time performance.
In another example based on a FAIRSeq neural machine translation model benchmark test, training that took 15 days on NVidia’s six-month-old DGX-1 server took less than 1.5 days on the DGX-2. That’s a 10x improvement in performance and productivity that any data scientist can appreciate.
On Software
Nvidia’s software is what’s enabling workloads—particularly deep learning workloads--to migrate from CPUs to GPUs. On this front Nvidia unveiled TensorRT 4, the latest version of its deep-learning inferencing (a.k.a. scoring) software, which optimizes performance and, therefore, reduces the cost of operationalizing deep learning models in applications such as speech recognition, natural language processing, image recognition and recommender systems.
Here’s where the breadth of Nvidia’s impact on the AI ecosystem was apparent. Google, for one, has integrated TensorRT4 into TensorFlow 1.7 to streamline development and make it easier to run deep-learning inferencing on GPUs. Huang’s keynote included a dramatic visual demo showing the dramatic performance difference between TensorFlow-based image recognition peaking at 300 images per second without TensorRT and then boosted to 2,600 images per second with TensorRT integrated with TensorFlow.
Nvidia also announced that Kaldi, the popular speech recognition framework, has been optimized to run on its GPUs, and the company says it’s working with Amazon, Facebook and Microsoft to ensure that developers using ONNX frameworks, such as Caffe 2, CNTK, MXNet and Pytorch, can easily deploy using Nvidia deep learning platforms.
In a show of support from the data science world, MathWorks announced TensorRT integration with its popular MATLAB software. This will enable data scientists using MATLAB to automatically generate high-performance inference engines optimized to run on Nvidia GPU platforms.
On Cloud
The cloud is a frequent starting point for GPU experimentation and it’s an increasingly popular deployment choice for spikey, come-and-go data science workloads. With this in mind, Nvidia announced support for Kubernetes to facilitate GPU-based inferencing in the cloud for hybrid bursting scenarios and multi-cloud deployments. Executives stressed that Nvidia’s not trying to compete with a Kubernetes distribution of its own. Rather, it’s contributing enhancements to the open-source community, making crucial Kubernetes modules available that are GPU optimized.
The ecosystem-support message was much the same around Nvidia GPU Cloud (NGC). Rather than offering competing cloud compute and storage services, NGC is a cloud registry and certification program that ensures that Nvidia GPU-optimized software is available on third-party clouds. At GTC Nvidia announced that NGC software is now available on AWS, Google Cloud Platform, Alibaba’ AliCloud, and Oracle Cloud. This adds to the support already offered by Microsoft Azure, Tencent, Baidu Cloud, Cray, Dell, Hewlett Packard, IBM and Lenovo. Long story short, companies can deploy Nvidia GPU capacity and optimized software on just about any cloud, be it public or private.
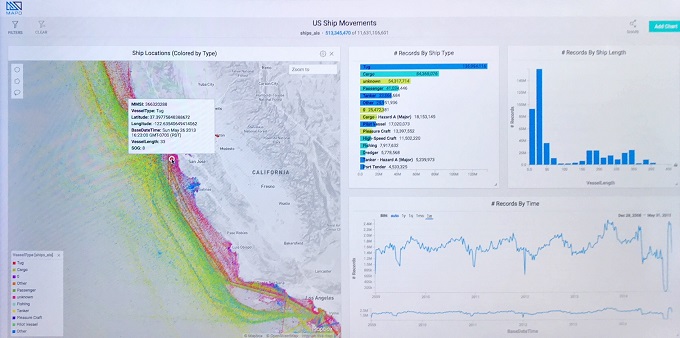
In an example of GPU-accelerated analytics, this MapD geospatial analysis shows six
years of shipping traffic - 11.6 billion records without aggregation - along the West Coast.
MyTake on GTC and Nvidia
I was blown away at the range and number of AI-related sessions, demos and applications in evidence at GTC. Yes, it’s an Nvidia event and GPUs were the ever-present enabler behind the scenes. But the focus of GTC and of Nvidia is clearly on easing the path to development and operationalization of applications harnessing deep learning, high-performance computing, accelerated analytics, virtual and augmented reality, and state-of-the art rendering, imaging or geospatial analysis.
Analyst discussions with Huang, Bill Dally, Nvidia’s chief scientist and SVP of Research, and Bob Pette, VP and GM of pro visualization, underscored that Nvidia has spent the last half of its 25-year history building out its depth and breadth across industries ranging from manufacturing, automotive, and oil and gas exploration to healthcare, telecom, and architecture, engineering and construction. Indeed, Nvidia Research placed its bets on AI – which will have a dramatic impact across all industries – back in 2010. That planted the seeds, as Dally put it, for the depth and breadth of deep learning framework support that the company has in place today.
Nvidia can’t be a market maker entirely on its own. My discussions at GTC with accelerated analytics vendors Kinetica, MapD, Fast Data and BlazingDB, for example, revealed that they’re moving beyond a technology-focused sell on the benefits of GPU query, visualization and geospatial analysis performance. They’re moving to a vertical-industry, applications and solutions sell catering to oil and gas, logistics, financial services, telcos, retail and other industries. That’s a sign of maturation and mainstream readiness for GPU-based computing. In one of my latest research reports, “Danske Bank Fights Fraud with Machine Learning and AI,” you can read about why a 147-year-old bank invested in Nvidia GPU clusters on the strength of convincing proof-of-concept tests around deep-learning-based fraud detection.
Of course, there’s still work to do to broaden the GPU ecosystem. At GTC Nvidia announced a partnership through which its open sourced deep learning accelerator architecture will be integrated into mobile chip maker Arm’s Project Trillium platform. The collaboration will make it easier for internet-of-things chip companies to integrate AI into their designs and deliver the billions of smart, connected consumer devices envisioned in our future. It was one more sign to me that Nvidia has a firm grasp on where its technology is needed and how to lay the groundwork for next-generation applications powered by GPUs.
Related Reading:
Danske Bank Fights Fraud with Machine Learning and AI
How Machine Learning & Artificial Intelligence Will Change BI & Analytics
Amazon Web Services Adds Yet More Data and ML Services, But When is Enough Enough?
Doug Henschen is former Vice President and Principal Analyst where he focused on data-driven decision making. Henschen’s Data-to-Decisions research examines how organizations employ data analysis to reimagine their business models and gain a deeper understanding of their customers. Henschen's research acknowledges the fact that innovative applications of data analysis requires a multi-disciplinary approach starting with information and orchestration technologies, continuing through business intelligence, data-visualization, and analytics, and moving into NoSQL and big-data analysis, third-party data enrichment, and decision-management technologies. Insight-driven business models are of interest to the entire C-suite, but most particularly chief executive officers, chief digital officers,…...
Read morePublished
Author
