Google launches Gemini, its ChatGPT rival, adds AI Hypercomputer to Google Cloud
Alphabet's Google has launched Gemini, its most powerful model designed to compete with OpenAI's ChatGPT, in three sizes Gemini Ultra focused on complex tasks, Gemini Pro, an all-purpose model, and Gemini Nano, which is aimed at on-device usage.
The Gemini 1.0 rollout will catch some folks by surprise given that there were reports that Gemini would be pushed to early 2024. With the introduction of Gemini, all three hyperscale cloud providers have announced or upgraded models in recent days. Amazon Web Services outlined Amazon Q at re:Invent. Microsoft is upgrading Copilot with the latest from OpenAI.
"These are the first models of the Gemini era and the first realization of the vision we had when we formed Google DeepMind earlier this year. This new era of models represents one of the biggest science and engineering efforts we’ve undertaken as a company," said Alphabet CEO Sundar Pichai.
In a blog post, Demis Hassabis, CEO of Google DeepMind, said the company set out to make Gemini multimodal from the start. Typically, large language models (LLM) have different modes stitched together.
Hassabis said:
"Until now, the standard approach to creating multimodal models involved training separate components for different modalities and then stitching them together to roughly mimic some of this functionality. These models can sometimes be good at performing certain tasks, like describing images, but struggle with more conceptual and complex reasoning.
We designed Gemini to be natively multimodal, pre-trained from the start on different modalities. Then we fine-tuned it with additional multimodal data to further refine its effectiveness. This helps Gemini seamlessly understand and reason about all kinds of inputs from the ground up, far better than existing multimodal models — and its capabilities are state-of-the-art in nearly every domain."
Google cited a bevy of benchmarks for Gemini and said the model "exceeds current state-of-the-art results on 30 of the 32 widely used academic benchmarks used in LLM research and development."
- AWS, Microsoft Azure, Google Cloud battle about to get chippy
- How much generative AI model choice is too much?
For instance, Gemini Ultra scored 90% on MMLU (massive multitask language understanding), which is based on a combination of 57 subjects, world knowledge and problem solving. Google said its approach to Gemini enables it to think more carefully before answering difficult questions.
In a chart, Google outlined Gemini benchmarks vs. ChatGPT. Gemini 1.0 fared well vs. ChatGPT, but lagged in HellaSwag, a benchmark for commonsense reasoning for everyday tasks. Both models scored about 53% on challenging math problems, which is still better than I'd do. Overall, Gemini 1.0 benchmarks are slightly better than the ChatGPT-4 comparison.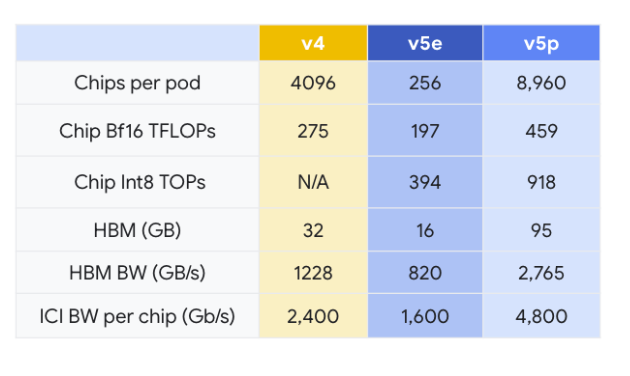
While these benchmarks for models are interesting, enterprises are likely to get a bit of Deja vu with the semiconductor benchmark battles. Read the fine print, conditions and realize that in real-world use cases a slightly better benchmark score may not matter.
According to Google, Gemini Ultra excels in "several coding benchmarks." Coding ability is perhaps the use case with the most returns for LLMs as developer productivity has been a game changer for enterprises.
Google also said that Gemini has built-in safety evaluations including safety classifiers to identify, label and sort out content that's toxic. Gemini Ultra is currently completing trust and safety checks before rolling out broadly. Bard Advanced will launch with Gemini Ultra early in 2024.
Gemini will be used to upgrade Google's Bard and Gemini Nano will power generative AI features on Pixel 8 Pro.
Infrastructure on Google Cloud
No model is complete without an announcement about training infrastructure and in-house processors.
Google trained Gemini on its in-house Tensor Processing Units v4 and v5e. Google is launching Cloud TPU v5p, which is aimed at training AI models.
Cloud TPU v5p, which powers a pod composed of 8,960 chips and an inter-chip interconnect at 4,800 Gbps/chip.
- Microsoft launches AI chips, Copilot Studio at Ignite 2023
- AWS presses custom silicon edge with Graviton4, Trainium2 and Inferentia2
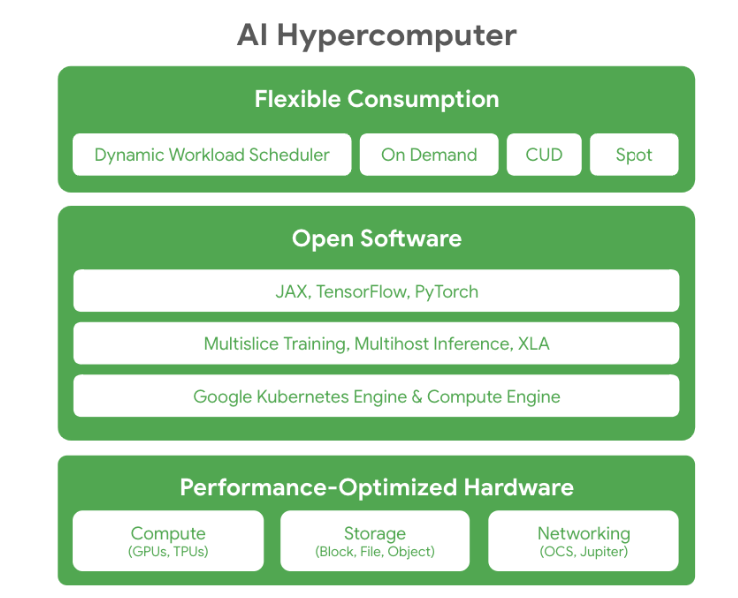
Those TPUs will be part of Google Cloud's upcoming AI Hypercomputer, a supercomputer that will include integrated hardware, open software and flexible consumption models.
Here's a look at the AI Hypercomputer stack:
Constellation Research analyst Andy Thurai said:
"Google is taking on competitors in three major categories -- OpenAI/Microsoft ChatGPT with their Gemini, AWS and NVIDIA on infrastructure with new TPU chips to become the AI training platform, and IBM/HP/Oracle/ with the AI Hypercomputer.
Gemini was delayed due to concerns about the readiness, safety concerns, and especially the problems with non-English queries. It is clear that Google wants to be careful with Gemini since it will be embedded in multiple products. That caution is another reason the live version got replaced with "virtual demos." But Google can't afford to wait with Gemini and lose mindshare as OpenAI/Microsoft and AWS continually release models.
Gemini has a few differentiators. First, Gemini is multimodal from the ground up. Technically, this LLM could cross the boundary limitations of modalities. Second, Google also released three model sizes rather than one size fits all categories. Third, there are safety guardrails to avoid any toxic content.
Bottom line: Google is trying to become a one stop shop for large enterprises to train their massive LLMs and run on Google Cloud."
Larry Dignan is Editor in Chief of Constellation Insights at Constellation Research, where he leads editorial coverage focused on enterprise technology, digital transformation, and emerging trends shaping the future of business. He oversees research-driven news, analysis, interviews, and event coverage designed to help technology buyers and vendors navigate complex markets with clarity and context. ...
Read morePublished
Author
