IBM Joins Hybrid, Multi-Cloud Data Science Chorus
IBM sings praises of build-anywhere, deploy-anywhere, open-source analytics. Here's a review of what's now a familiar refrain.
Lots of big tech vendors are now singing from the same hymn book when it comes to data platforms and data science. The message to customers is that they’re offering a range of deployment options, including hybrid-cloud and multi-cloud for agility. They’re also saying they’re open, supporting a range of open source languages, notebooks, frameworks and libraries. IBM hit on all these notes at its November 2 Cloud and Cognitive Summit in New York, but how does it stand out?
IBM’s Cloud and Cognitive Summit marked the introduction of two new tools and a new Hadoop and Spark service on the Watson Data Platform. Executives also revealed the Kubernetes-based containerization of IBM Data Science Experience, a move they said will enable organizations to build and deploy models wherever the data lives. Here’s a deeper look at the details.
It Starts with the Platform
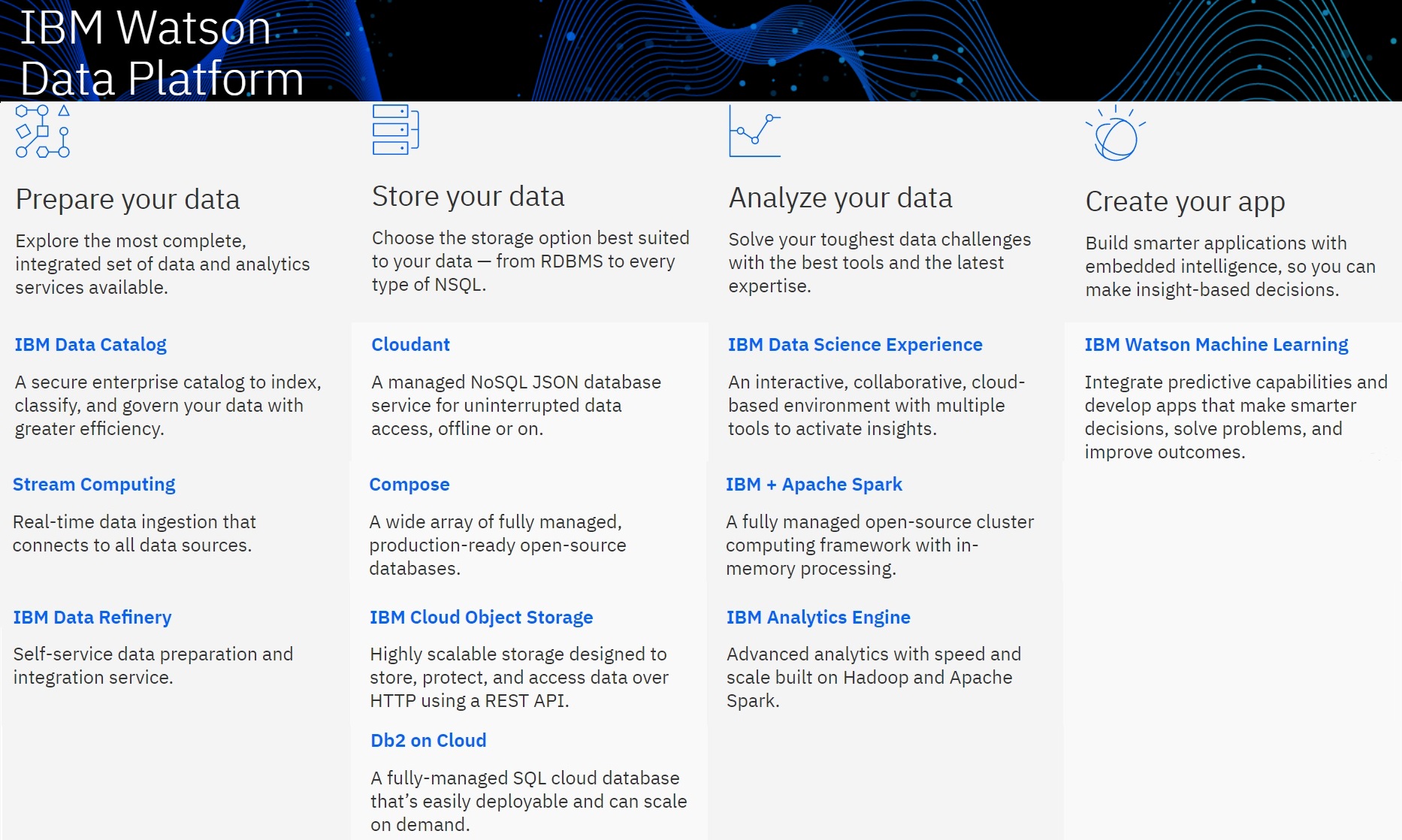
“You can’t get to AI without IA.” That’s how Rob Thomas, general manager of IBM Analytics, explained the need for solid information architecture as an underpinning of artificial intelligence. Indeed, data management comes first, and IBM describes its Watson Data Platform as a kind of operating system for modern, data-driven applications, This cloud-based platform was launched last fall the Strata NY Conference 2016. The Cloud & Cognitive Summit was the launching pad for two new platform capabilities: Data Catalog and Data Refinery.
Data Refinery checks the box for self-service data-prep capabilities, though my sense is that it’s a starting point (see analysis below). Data Catalog helps users, particularly business users, get their arms around available data by tagging or ingesting preexisting metadata and creating an index of all available assets. IBM says its catalog is not just about data – whether on-premises or in the cloud, structured and unstructured. Using an API, IBM says admins can also inventory assets including models, pipelines and even dashboards.
The Summit also marked the general availability of the IBM Analytics Engine, which is the company’s new Hadoop and Apache Spark service. IBM already offered Hadoop and Spark services, of course, but the Analytics Engine was hatched this summer after the company ended development or its own IBM BigInsights distribution and related cloud service in favor of a partnership with Hortonworks. The new service separates storage and compute decisions, with persistence options including a new IBM Db2 Event Store that uses the Parquet data format to deliver what IBM says is much better performance that ordinary object stores.
Constellation’s analysis: Access control, governance and a shared collaborative and community workspace are the key concepts behind Watson Data Platform. The platform gives large organizations with lots of data sources, data pipelines, models and data-driven applications a centralized, project-oriented home in which to prepare, store and analyze data and then deploy and manage models. The analyze, deploy and manage aspects are handled with the IBM Data Science Experience (detailed below).
With the new Data Catalog and Data Refinery capabilities, Watson Data Platform adds depth as a data-management and governance layer. Seeing the demos and talking to multiple executives at the Summit, I came away wanting more detail. I liked the cataloging vision of being able to inventory pipelines, models, dashboards and other assets as well as data. But there wasn’t a lot of nitty, gritty insight into the out-of-the-box capabilities versus what you can do with APIs. As you can read in my Constellation ShortList on Data Cataloging, there’s a lot to a state-of-the-art product in terms of crawling sources, automatically tagging, applying machine learning to track and understand access patterns, supporting collaboration around assets and offering intelligent recommendations to catalog users. I need to see more and talk to customers before I would add IBM Data Catalog to my ShortList.
A couple of executives I spoke to at the Summit described the Data Refinery as a work in progress. The current plan is for the Refinery to be an extra-cost option, but as a buyer, I’d want to see the list of out-of-the-box connectors and details on assisted data-prep and recommendation capabilities, as outlined in my Self-Service Data Prep ShortList. At this writing there’s a free beta available, so it’s possible to do some comparison shopping before paying extra for this feature of the Watson Data Platform.
Every modern data platform worth its salt now separates storage and compute decisions, and the IBM Analytics Engine was an obvious and inevitable update given the end of BigInsights development. IBM has joined Microsoft, Oracle and Pivotal, among others, in offering cloud services based on the ODPi standard. Adding the Event Store is a good step for performant object storage, though I have no idea why IBM has saddled it with “Db2” branding given that it has nothing to do with that commercial relational database.
Data Science Experience Goes Multi-Cloud
IBM introduced Watson Data Platform and Data Science Experience (DSX) back in 2016 with support for open-source options including Apache Spark, R, Python, Scala and Jupyter notebooks. At last week’s event it joined the chorus of notable vendors (also including Microsoft, SAS and SAP) talking up hybrid and multi-cloud freedom of choice for data science work. In the case of DSX this multi-cloud support has been made possible by the recent containerization of the product by way of Kubernetes, so it can be deployed in Docker or CloudFoundry containers “wherever the data lives.” There was also mention of DSX integration with GitHub, although this is apparently in the formative stages (see analysis below).
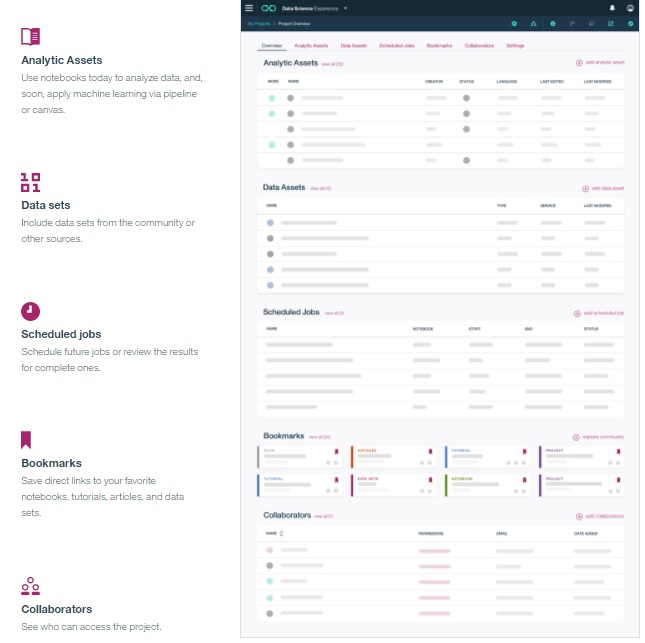
IBM Data Science Experience provides a project-oriented management layer for unified,
controlled access to data, models, pipelines, notebooks and collaborative work spaces.
DSX is both a part of and, optionally, independent from Watson Data Platform as DSX Local, which can run behind corporate firewalls or on desktops. DSX provides permission-controlled, collaborative access to projects, data, data science tools, services, and a community space. With its support for R, Python and Scala and Jupyter and (now on DSX Local) Apache Zeppelin notebooks, DSX users can tap popular open source libraries including Spark MLlib, TensorFlow, Caffe, Keras and MXNet.
IBM says DSX’s big differentiator is its ability to support “clickers as well as coders.” I covered the coders part above. Clickers, meaning non-data scientists, use DSX as a gateway to SPSS, which is IBM’s commercial offering supporting point-and-click and drag-and-drop modeling and statistical analysis. SPSS is also the source of IBM’s machine-learning-driven, automated model development, deployment and optimization capabilities, which were rebranded from IBM Predictive Analytics to Watson Machine Learning in October 2016.
Constellation’s analysis: IBM and other leading commercial vendors have gotten the message that data scientists want open source options and hybrid and multi-cloud deployment options through which they can avoid vendor lock-in. This year I’ve seen lots of analytics and data science platform progress announcements, from Cloudera, Databricks, IBM, and Microsoft to Oracle, SAP, SAS, Teradata and more. Common themes include support for Spark for processing; object stores for the separation of storage and compute; column stores for performance; R, Python and, in some cases, Scala, for language support; Jupyter and Zeppelin notebook support; and access to Spark ML, TensorFlow, Caffe, Keras, and other leading frameworks and libraries.
These data science platforms provide a centralized environment for securely sharing access to data, collaborating around models and then deploying, monitoring and maintaining models at scale. Cloudera is focused on doing this work on its own Hadoop/Spark platform whereas IBM, Oracle, Microsoft, SAP and SAS also integrate with their respective commercial data warehousing platforms, streaming capabilities, analytics tools and libraries, and public clouds.
Amazon Web Services and Google both have enviable data platform and data science portfolios as well, but their emphasis is on doing it all in their respective public clouds, which isn’t always possible for big enterprises with lots of systems and data still on premises. IBM, Microsoft and SAS have embraced containerization for hybrid and multi-cloud deployment, acknowledging that customers want to be able to analyze data and build, deploy and run models anywhere, including rival public clouds.
IBM and SAS have had a lot to say about support for open source languages and libraries (and in IBM’s case, Apache Spark), but their commercial analytics software offerings are also part of their Data Science platforms. As a customer, I’d want to know exactly what commercial software I’m licensing or subscribing to along with the platform, the terms of that investment and whether there are options to consume that software in an elastic, services-oriented model on-demand.
I was heartened to hear that IBM is also pursuing GitHub integration with DSX, but few details were available on this push. Among the many data science platform announcements I’ve seen this fall, I’d have to say I was most impressed by Microsoft's next generation of Azure ML (currently in beta). Microsoft has integrated with GitHub to track the end-to-end lifecycle of code, configurations and data (as well as the lineage and provenance of data) used throughout the model development/deployment/optimization lifecycle.
Being able to track data lineage is crucial to satisfying regulatory requirements in the banking and insurance sectors. It’s also what’s needed to satisfy General Data Protection Regulation (GDPR) requirements looming in the European Union and to meet growing demand for explainable and interpretable predictions and recommendations. I suspect IBM is on the same track to bolstering data-governance capabilities with GitHub.
In a separate announcement on November 2, IBM, Hortonworks and ING Group are working with the Linux Foundation to promote an open data governance ecosystem that will define interfaces for diverse metadata tools and catalogs to exchange information about data sources, including where they are located, their origin and lineage, owner, structure, meaning, classification and quality. This work stands to benefit both cataloging and, more importantly, data-governance and GDPR compliance.
Related Reading:
Microsoft Stresses Choice, From SQL Server 2017 to Azure Machine Learning
Oracle Open World 2017: 9 Announcements to Follow From Autonomous to AI
SAP Machine Learning Plans: A Deeper Dive From Sapphire Now
Doug Henschen is former Vice President and Principal Analyst where he focused on data-driven decision making. Henschen’s Data-to-Decisions research examines how organizations employ data analysis to reimagine their business models and gain a deeper understanding of their customers. Henschen's research acknowledges the fact that innovative applications of data analysis requires a multi-disciplinary approach starting with information and orchestration technologies, continuing through business intelligence, data-visualization, and analytics, and moving into NoSQL and big-data analysis, third-party data enrichment, and decision-management technologies. Insight-driven business models are of interest to the entire C-suite, but most particularly chief executive officers, chief digital officers,…...
Read morePublished
Author
