Amazon re:Invent – game-changer or just another show in town?
I was privileged to attend the Amazon AWS re:Invent conference for the first time this year as an Analyst, though been to re:Invent many times as a vendor/consultant. As always, Amazon puts up a big show! Other than the changes at the helm (Adam replacing Andy), there were also some cultural changes that I sensed throughout the conference.
Here are some of their top announcements:
- AI/ML-based Demand Forecasting – AWS is bringing the power of demand prediction to the masses. Amazon.com has used this for many years as a competitive advantage to grow into a retail giant by using ML for demand forecasting, improved purchasing systems, automatic inventory/order tracking, distribution/supply chain management, operational efficiency, and customer experience. Now they are offering it to others.
- Hardware refresh – AWS gets a refresh of processors with AMD's EPYC processors (M6a), Graviton ARM processor, nVIDIA T4G tensor GPUS. Particularly this is appealing to VM users, as there is a 35% performance improvement per Amazon.
- Enterprise Robotics Toolbox – AWS IoT RoboRunner and the associated robotics accelerator program allow building robot and IoT eco-systems on the cloud.
- 5G – AWS allows spinning up private 5G mobile networks in days. This is their attempt to get into mobile and networking in a massive way.
- AWS Mainframe modernization service – The mainframe migration is slower than AWS had hoped for. This is a big push to help move those mainframe workloads to AWS.
Below are the AI/ML specific announcements from Amazon:
SageMaker, AWS' machine learning (ML) development platform, gets modest enhancements to attract a newer set of users – the business analysts. A major problem in AI, ML development now is the limitation of Data Scientists and the cost associated with building experimental models. And there is also the cost of produtionizing, optimizing them in production once it is ready to go. Amazon is trying to democratize both of these functions with several announcements covered below.
1. SageMaker Canvas
SageMaker platform gets a new tool to build no-code ML models using studio with a point-and-click interface. You can build and train models from the Canvas using wizards. You can upload data (CSV files, Amazon Redshift, Snowflake are the current options), train the models, and can perform predictions in an iterative loop until you can perfect the model. The models can be easily exported to SageMaker studio for production deployment or sharing with other Data Scientists either for improvement or for validation and/or approval.
It uses the same engine as Amazon Sagemaker for data cleanup, data merger, and to create multiple models, and for choosing the best performing ML model.
Keep in mind this is NOT the first time Amazon dabbled on this. They tried it many years ago, circa 2015, Amazon Machine Learning (which was limited to Redshift and S2 at that time). Amazon deprecated that in 2019 as adoption was slow and the interface was a bit clunky.
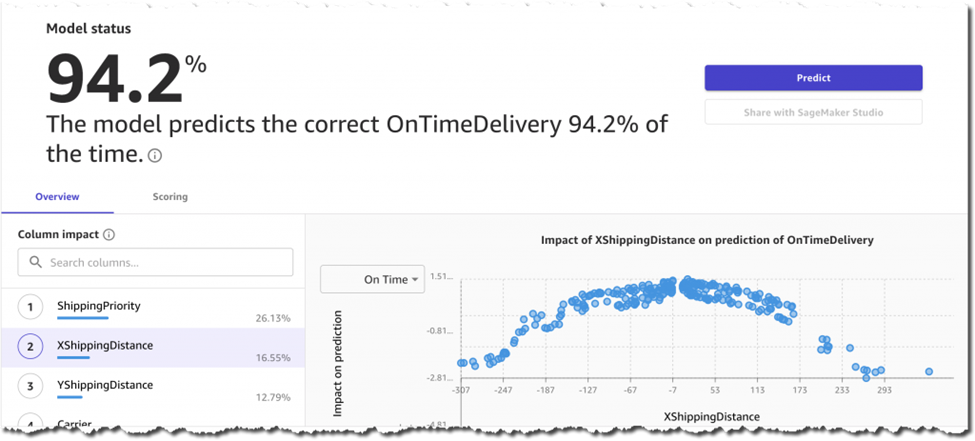
[Image source: Amazon]
My View: This is a good step towards democratizing ML model creation. Now business users can easily build simple models and experiment instead of relying on expensive Data Scientists. What I particularly like is the fact that it gives the accuracy of model prediction, 94.2% in the case above, which can instill confidence with a non-data scientist on whether they built a model that is good enough or if they have to escalate to an expert for fine-tuning.
The interface is still a bit awkward for the general business user. Currently, the data input is very restricted to tabular data and not integrated with their own data prep tools. The documentation is not that great, especially if you are a business user you can get lost fairly quickly. They also need to produce a lot of training videos to make this work.
It is only a slight improvement over the deprecated Amazon Machine Learning. It is very limited to 3 types and doesn't address the unstructured data or deal with video, audio, NLP, Ensembling, etc.
Verdict: Average. Overall it comes across as a mature MVP candidate. Still a lot of work needs to be done for it to be enterprise business user ready.
2. SageMaker Studio Lab
Amazon SageMaker Studio Lab (light version of SageMaker Studio based on JupyterLab) is a free machine learning (ML) development environment that provides the compute, storage (up to 15GB), and security—all at no cost—for anyone to learn and experiment with ML. This setup requires no AWS account, no credit card, and no extended sign-ups, just an email address. You don't need to configure infrastructure or manage identity and access or even sign up for an AWS account. SageMaker Studio Lab accelerates model building through GitHub integration, and it comes preconfigured with the most popular ML tools, frameworks, and libraries to get you started immediately. SageMaker Studio Lab automatically saves your work so you don't need to restart in between sessions.
My View: This option is to attract developers who wants to try before they buy and is similar to Google's CoLab environment which has become popular with ML beginners. What makes this interesting is the option to choose between CPU (12 hours) or GPU (4 hours) combination for the project. For example, a Convolutional Neural Network (CNN) or a Recurrent Neural Network (RNN) might require intensive GPU sessions whereas other algorithms might be ok to execute on CPUs. The generous 15 GB storage allows for retention of the project and data to continue experimentation over multiple sessions/days. Given that this is JupyterLab based (popular among Data Scientists) instead of yet another Amazon tool, getting traction with Data Scientists should be fairly easy. The datasets and Jupyter notebooks can be easily imported from Git repo or from the Amazon S3 bucket.
Verdict: Average. This can attract two user communities:
- The enterprise users who want to do side projects without enterprise approval to prove the concept rather than waiting for extended periods to get approval to open a paid AWS account.
- Run hackathons with a codebase or ideas from a common repository (Github) and have as many participants join the hackathon for ideation. This is a great usecase for enterprises that run hackathons often and worried about configuring a lab environment, providing access to the enterprise network, and the costs associated for all the hackathoners.
3. SageMaker Serverless Inference (and Recommender)
Another brand-new option was introduced at the re:Invent. This allows users to deploy ML models, anywhere, anytime, on the Amazon serverless platform and pay only for the time used. No need for extensive infrastructure provisioning and set-up. With this option, not only can AWS deploy quickly, but can also scale up, down, and out underlying infrastructure automatically based on demand. The charge is only for the time the code is run and the amount of data processed, not during idle times. The billing is in millisecond increments.
An added feature that goes along with the above, is the Amazon SageMaker Inference Recommender. This service enables the Data Scientists (or anyone who is deploying the ML models) to select the most optimized compute for the deployment of the ML models. It recommends the right instance type, instance count, container parameters, etc. to get the best performance at a minimal cost. It also allows MLOps engineers to run load tests against their models in a simulated environment. This is a great way to stress test ML models at varying loads to see how they will behave in production.
My View: Most often the ML model deployment is very complicated. Data Scientists are not very good with coding, infrastructure, and cloud deployments. After their experimentation is done, they have to wait for Data Engineering help, and sometimes deployment/release team help to make it work. By taking that portion out of the equation, Data Scientists can run their productionized experiments as soon as it is ready.
Verdict: Good. Probably this is the most noteworthy announcement of all. Deploy the ML model as soon as it is ready. Also, letting ML models exploit the fullest capabilities of the Cloud.
4. SageMaker Ground Truth Plus
A turnkey service that can elastically expand the expert contract workforce that is available on-demand for data labeling services to produce high-quality datasets fast and reduce costs up to 40%. Outsourcing of data labeling and image annotations becomes easier allowing Data Scientists to concentrate on more valuable work. This service also uses ML techniques, including active-learning, pre-labeling, and machine validation (This is an additional feature that was not available with the Amazon Mechanical Turk service). Currently, it is available only in the US East AWS region though Amazon expects to expand this service quickly to other regions.
My View: This already existed as part of Amazon Mechanical Turk. Besides, there are hundreds of companies specializing in Human-in-the-loop (HITL) producing high-quality, industry-specific data sets as well as synthetic data. While image annotation and data labeling are the hardest problems to solve in ML modeling, this service is just relabeling of existing services in my view. There are two distinct advantages to using Amazon's service vs others. First, the workflow, dashboarding, and outsourcing workflow management are automated. Second, Amazon claims the ML systems learn on the job and can kick in and start to "pre-label" the images on behalf of the expert workforce. This is a tall claim especially because the whole idea of having this in place is to have a human be a source of truth instead of a machine.
Verdict: Below Average. Amazon wants to automate the data labeling, image annotation, and machine validation eventually and this is a good first step in that direction.
5. SageMaker Training Compiler
A new service that aims to accelerate the training of deep learning (DL) models by compiling the python code to generate GPU kernels. It accelerates training jobs by converting DL models from their high-level language representation to hardware-optimized instructions that train faster than the ordinary frameworks. It uses graph-level optimization, dataflow-level optimizations, and backend optimizations to produce an optimized model that efficiently uses hardware resources and, as a result, trains the compiled model faster. It does not alter the final trained model but increases the efficiency using the GPU memory and fitting a larger batch size per iteration. The final trained model from the compiler-accelerated training job is identical to the one from the ordinary training job.
My View: Multi-layered DL models are very compute/GPU intensive to run. A lot of data engineering time is spent on optimizing the models for the run environment. While Amazon doesn't give specifics on how much time/cost savings after the optimization/compilation, this could be huge in cutting down the DL multi-layered neural network model training costs.
Verdict: Above Average. If it works as claimed, this can result in huge savings for enterprises as a lot of time and money is spent on training DL models.
6. Amazon Graviton v3 (Plus Trn1 and Trainium)
A custom-built ARM-based chip for AI plus a compute instance (C7G) that is built on that processor. Amazon claims a 3x boost for ML workloads while reducing the energy by 16%.
My View: Another crowded market. Not only nVIDIA is dominant in this space, but there are other smaller competitors with advanced technologies such as Blaize, Hailo, SambaNova Systems, Grahcore, and the bigger ones from AMD, Apple, Google, Intel, IBM, etc.
Verdict: Below Average.
And a few more related announcements from AWS in the AI/ML area:
- Contact Lens – A virtual call center product (based on NLP) that transcribes calls via Amazon's cloud contact center service.
- Lex – An automated chatbot designer which helps in building conversational voice and text interfaces. The designer uses ML to provide an initial design that can be refined to customize based on needs.
- Textract – A ML service that automatically extracts text, handwriting, and data from scanned documents. It can extract information from IDs, licenses, passports, etc. for specific information such as date of birth, name, address, etc.
- CodeGuru Reviewer Secret Detector – An automated tool that reviews and detects in source code/config files. Most times developers hard-code information such as API keys, passwords, etc. This augments the AI-powered code quality tool CodeGuru.
My overall POV
AWS always used to come across as a landing place to attract the digital innovators to experiment, innovate and then productionize. They always had a good story at re:Invent to attract the bleeding edge innovators. This time I felt they missed that beat a little. Overall, it came across as less innovative and more incremental story to what they already have. No earth-shattering new initiatives that blew me away. It could be because they wanted to play it safe with the change at the helm.
On the AI front, the democratization of AI is coming to move the AI modeling away from the expensive Data Scientists. AWS is giving you options to create, train, and productionize ML models with ease. They are trying to drive more people (business users) towards their cloud. They also want to compete not just for regular compute workloads but also for the newer AI/ML workloads.
Democratization of AI is coming. Amazon fired the first shots in the right direction. We need to wait and see the market traction and whether Amazon will continue to improve on these services or deprecate some of these services.
About Andy Thurai Andy Thurai is an accomplished IT executive, strategist, advisor, enterprise architect and evangelist with more than 25 years of experience in executive, technical, and architectural leadership positions at companies such as IBM, Intel, BMC, Nortel, and Oracle. Andy has written more than 100 articles on emerging technology topics for publications such as Forbes, The New Stack, AI World, VentureBeat, DevOps.com, GigaOm and Wired. Andy’s fields of interest and expertise include AIOps, ITOps, Observability, Artificial Intelligence, Machine Learning, Cloud, Edge, and other enterprise software. His strength is selling technology to the CxO audience with a value proposition rather than the usual technology sales pitch. Find more details and samples of Andy’s work on his…...
Read morePublished
Author
