Nvidia releases MLPerf Training results as it ramps AI factories
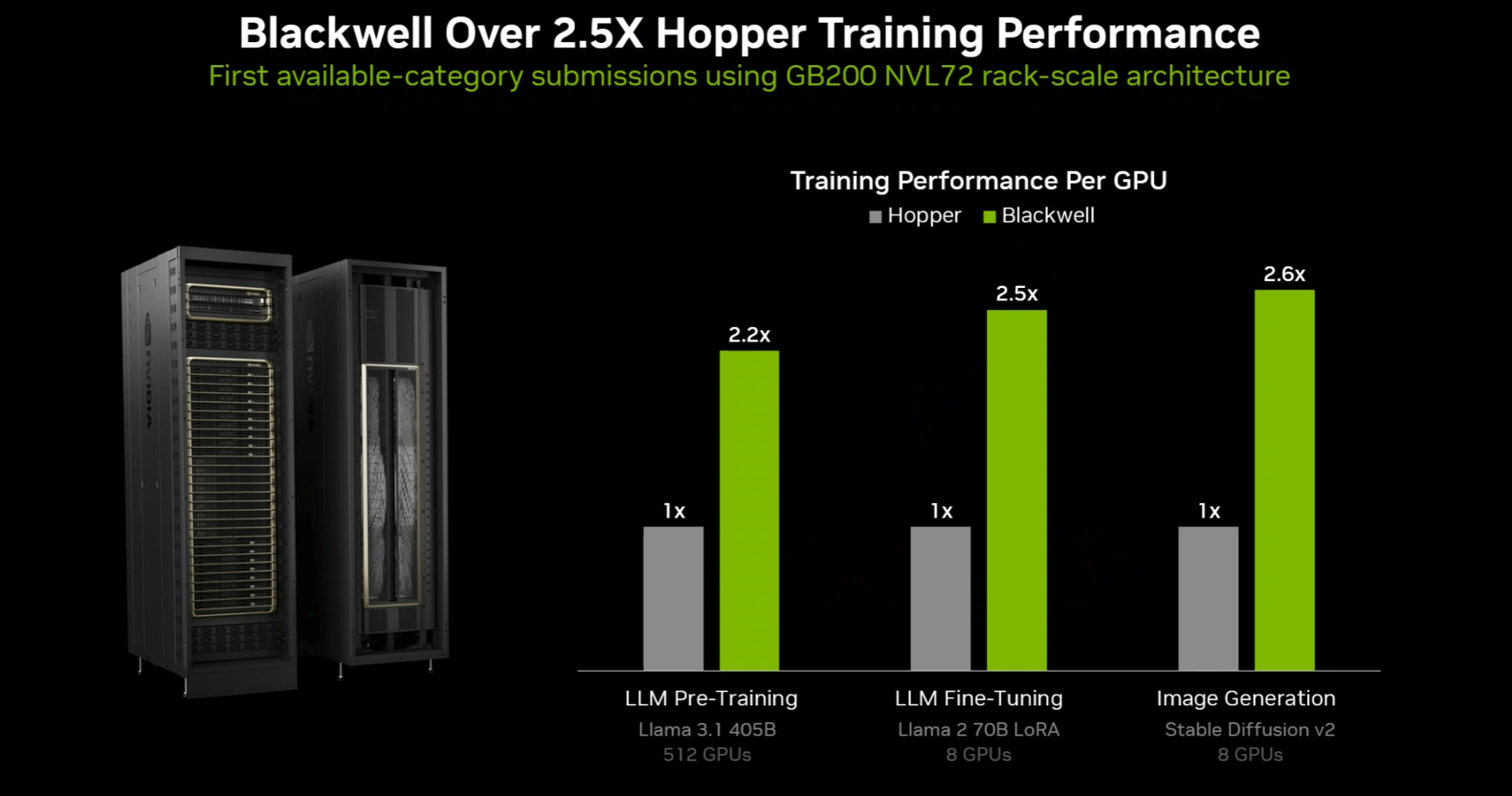
Nvidia said its GB200 NVL72 rack scale systems outperformed Hopper by a wide margin based on MLPerf Training submissions across categories.
The company outlined the benchmark as its Blackwell instances--GB200 NVL72--are now generally available from Microsoft Azure, CoreWeave and Google Cloud with more providers on deck.
Nvidia was the only platform that submitted for all benchmarks including the new Llama 3.1 405B pre-training test. Nvidia was also out to show the benefits of its complete stack with fifth-gen NVLink and NVLink Switch delivering 2.6x more training performance per GPU compared to Hopper.
- Nvidia Q1 strong, continues to ride data center demand
- Nvidia launches NVLink Fusion to connect any CPU with its GPU, AI stack
- Nvidia NeMo Microservices generally available, aims for AI agent data flywheel
- Nvidia GTC 2025: Six lingering questions
- Nvidia launches DGX Spark, DGX Station personal AI supercomputers
- Nvidia launches Blackwell Ultra, Dynamo. outlines roadmap through 2027
Here's a look at the results, which can be found at Mlcommons.org, which oversees MLPerf Training metrics. MLPerf was developed by MLCommons Association to create a standard benchmark for AI workloads. The results are peer reviewed.

In a 2023 presentation on Hopper performance, Microsoft Azure was predominantly featured. This version of MLPerf Training performance was more about the AI factory. Constellation Research analyst Holger Mueller said:
"Nvidia once again has shown that it provides the best multi-cloud and on premise AI architecture for all three critical training use cases – pre-training, post training and test time scaling. Adoption across cloud and hardware vendors remains impressive. Apart from Oracle, the big three cloud providers are not part of the current Nvidia presentation. Microsoft Azure was a key feature back in fall of 2023. It is too early to overinterpret any of these changes in the presentation – but all three major cloud providers also provide their inhouse AI chip architectures."
The AI factory strategy
The MLPerf Training metrics are just part of Nvidia's overall AI Factory strategy. Nvidia CEO Jensen Huang has repeatedly argued that AI factories are a trillion-dollar opportunity that will replace traditional data centers. Every company will eventually have an AI factory to power operations.
According to Nvidia, AI factories will generate revenue as we move to a token-based, data economy. The job for Nvidia is to build that optimal integrated stack of GPUs, compute, networking and storage to efficiently scale to gigawatt AI factories. Nvidia's ultimate mote is likely to be its application stack that features everything from models, AI agents, digital twins and an enterprise suite.
These AI factories will come in four flavors: Cloud, enterprise, sovereign AI and industry-focused.
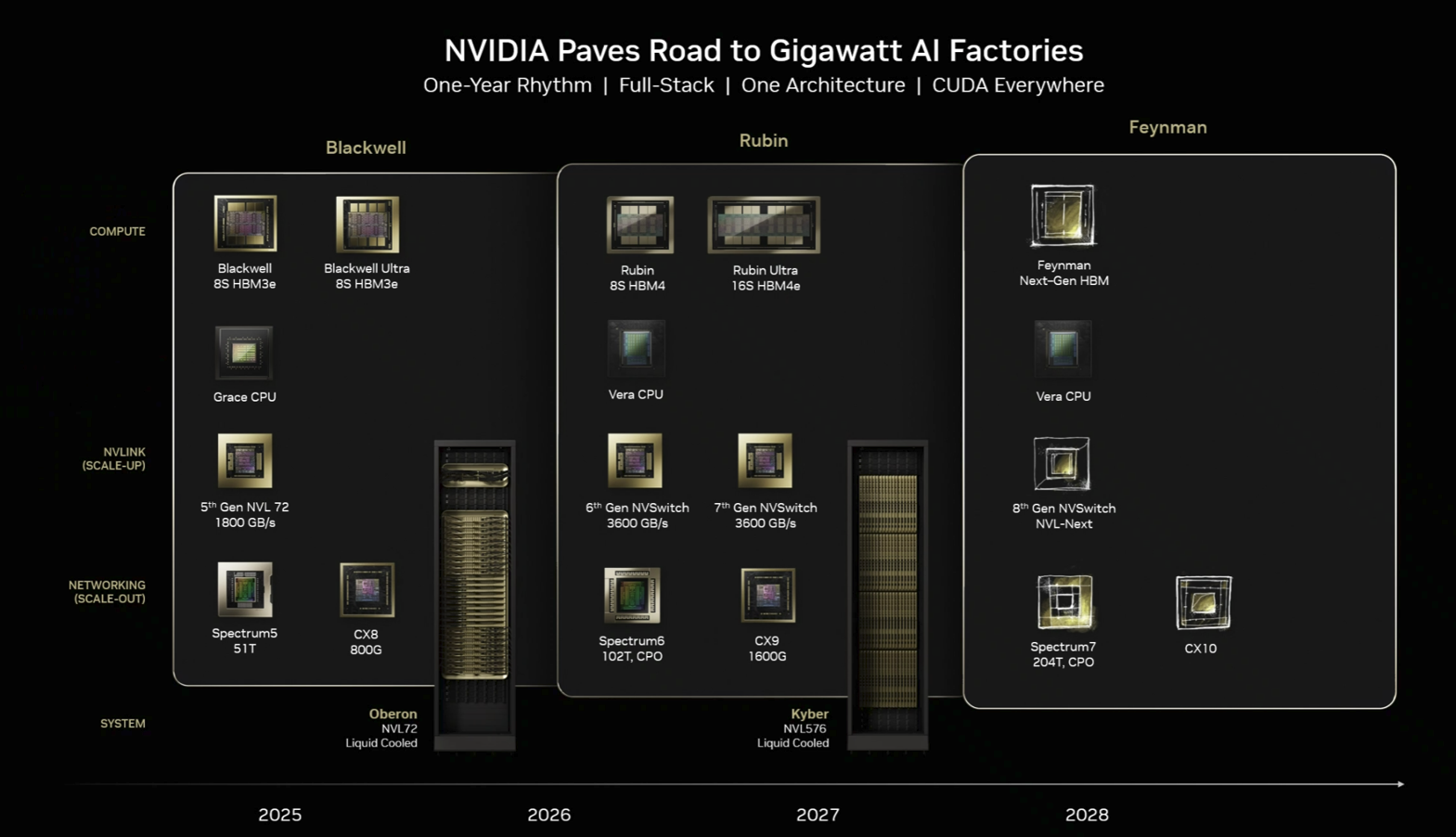
Nvidia will need to show performance gains annually to justify its annual cadence for AI infrastructure. Here's what's on tap.
- Blackwell (2025): Current generation with GB200 and GB300 variants
- Rubin/Rubin Ultra (2026): Next generation
- Kyber (2027): Future architecture
- Fineman (2028): Long-term roadmap
Larry Dignan is Editor in Chief of Constellation Insights at Constellation Research, where he leads editorial coverage focused on enterprise technology, digital transformation, and emerging trends shaping the future of business. He oversees research-driven news, analysis, interviews, and event coverage designed to help technology buyers and vendors navigate complex markets with clarity and context. ...
Read morePublished
Author
