Will IonQ make quantum computing enterprise relevant in 2025?
Editor in Chief of Constellation Insights
Constellation Research
Larry Dignan is Editor in Chief of Constellation Insights at Constellation Research, where he leads editorial coverage focused on enterprise technology, digital transformation, and emerging trends shaping the future of business. He oversees research-driven news, analysis, interviews, and event coverage designed to help technology buyers and vendors navigate complex markets with clarity and context. ...
Read more
This post first appeared in the Constellation Insight newsletter, which features bespoke content weekly.
IonQ, seen as one the major players in quantum computing, is arguing that enterprise relevance for its nascent market will be here in 2025--well before most observers are expecting.
That argument, made during IonQ's Analyst Day Sept. 19, is notable and may surprise folks that are betting that quantum computing will have enterprise relevance in a decade or so. Chuckle if you will, but I'll argue it's worth hearing IonQ out as it develops its #AQ 64 quantum system for 2025 commercial deployments.
First, let's state the obvious--quantum computing is in the early stage. In some ways, quantum computing is a fascinating market that could be the next big thing after generative AI, cloud, mobile, Internet and personal computing. It's not a question of IF quantum computing takes off, but WHEN.
You can see Constellation Research Shortlists from Holger Mueller to get the lay of the quantum computing land.
IonQ's financials tell the tale of early-stage markets. For instance, IonQ has an estimated $52.5 million in bookings estimated for fiscal 2023, but year-date-revenue through June 30 was $9.8 million with a net loss of $71.05 billion. IonQ's second quarter revenue was $5.5 million, up from $2.6 million a year ago. The company does have more than $500 million in cash to figure things out and executives noted IonQ will be self-sufficient without raising more dough.
Whether IonQ is worth a market capitalization of more than $3 billion remains to be seen.
CEO Peter Chapman made the argument that IonQ can be one of those generational companies, but in the meantime, it's hiring a lot of talent from the likes of Nvidia, Microsoft, Amazon, Oracle, Uber and Apple. IonQ has also partnered with QuantumBasel to establish a European quantum data center housing its #AQ 35 and #AQ 64 systems, signed a memorandum of understanding with South Korea's Ministry of Science and ICT.
Here's a look at my takeaways from IonQ's Investor Day as I sat through 5 hours of presentations and 103 slides, so you didn't have to.
The big picture. Quantum computing will be important, but the big question is when. Chapman argued that quantum computing will be enterprise relevant and solve real problems when its AQ 64 system scales up in 2025. Chapman said there's a big difference between solving real problems and waiting until quantum supremacy or quantum advantage to do anything. "We do not care about quantum advantage or quantum supremacy," said Chapman. "The test for me is this. Can I solve a customer problem with a better mousetrap at a better price? Our goal is to build quantum computers that solve problem for customers."
IonQ Thomas Kramer added that "it's too late to start a quantum computing company if you wait for quantum supremacy."

IonQ is pragmatic. A deep dive into the company's production and engineering plans revolved around usage of common parts, modularity and rack-mounted systems. Sure, IonQ's presentation was as quantum geeky as the rest of the field, but the company is homed in on solving problems and setting the stage for on-premises deployments, servicing and maintaining systems as easily as possible.
There's a solid roadmap and IonQ has customer references and use cases. IonQ outlined three customers where it has helped develop algorithms that can scale in future quantum systems. The general idea: Develop the algorithms now for quantum so when the compute lands you'll be ready to roll. Those customers were also heavy hitters: Airbus, Hyundai, GE Research and Air Force Research Laboratory.
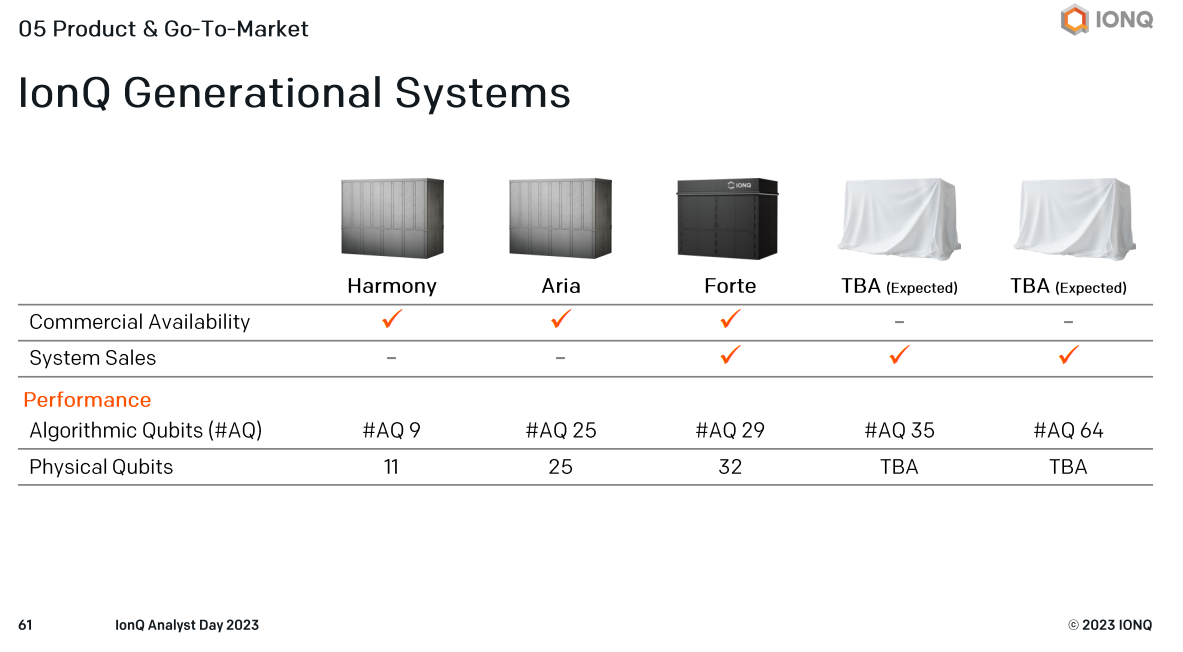

The company also is self-aware. IonQ has added strong executives, outlined a strong plan and has matured a lot since its October 2021 special purpose acquisition company (SPAC) IPO. Executives noted that IonQ has evolved from an academic and research driven organization to one that is focused on engineering. The next evolution will be moving from an engineering focused org to a product focused one. That evolution to be product focused will be "the next phase over the next several years," said Chapman.
Today, IonQ is engineering driven and that means tackling issues like error correction. Chapman and his team noted that A64 may not require error correction since it'll be able to mitigate issues ahead of time. "Error mitigation is a statistical approach to remove errors before systems are delivered to the customer," said Chapman. IonQ is pursuing both options at this phase of A64 development.
IonQ is more of a services firm today. IonQ is public but still an early-stage company that talks in terms of bookings and interest without actual sales. IonQ looks like more of a services firm as it develops products, algorithms and its ecosystem. The company will sell hardware and has multiple revenue options, but today it's helping customers with know-how, proofs of concepts and applications and use cases. This approach isn't surprising and there's precedent. Palantir and C3 AI were more consulting and services firms before becoming more product focused.
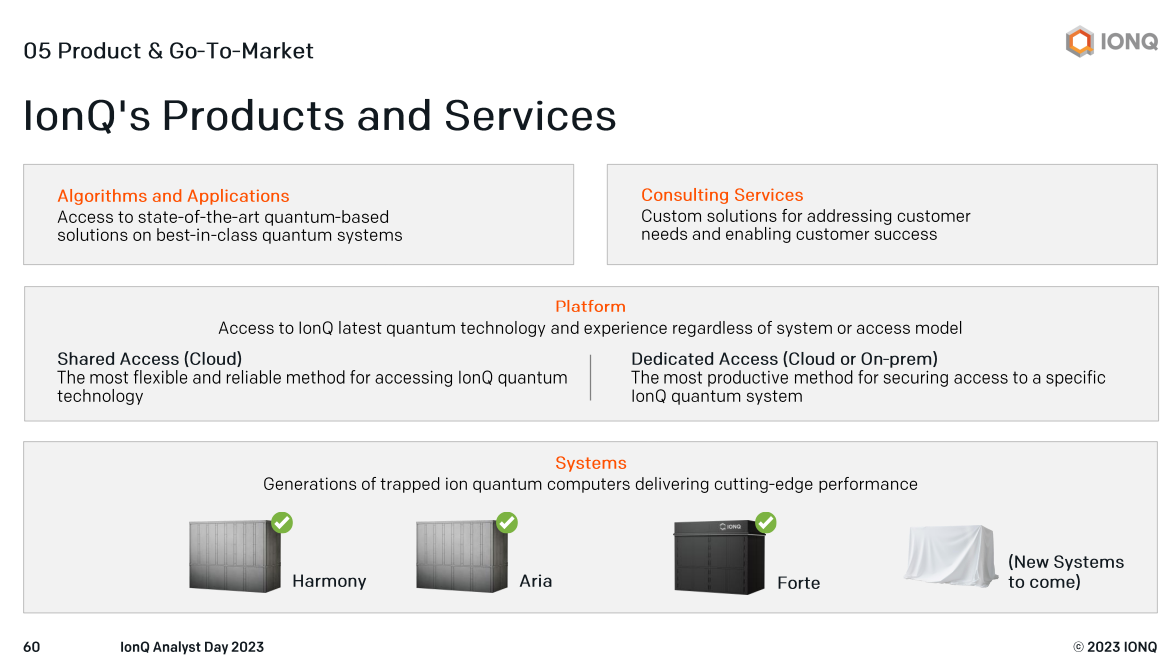
Manufacturing and supply chain are big unknowns. IonQ is building its manufacturing facility in Seattle, but it remains to be seen if it can deliver quantum systems at scale. IonQ has to build out its supply chain, source components, vertically integrate as needed and decide what parts it needs to create itself. IonQ's Seattle Manufacturing Hub and Data Center is set to start manufacturing in the fourth quarter.
Software will be critical. IonQ said that its software approach will be critical for everything from reducing noise in quantum systems, error mitigation and connecting to the broader ecosystem that'll include quantum processors, GPUs and CPUs. In addition, software will need to be developed for quantum systems while still working with classic computing.

What does the revenue model look like in the future? Executives walked through the go-to-market approach and future revenue streams. Production systems for commercial, government and academia will create hardware revenue, but there will also be access agreements, usage based, and work completed models. Broadly speaking, IonQ revenue drivers in the future include:
- Application co-development where IonQ partners with companies to develop end-to-end quantum systems.
- Partner cloud access via hyperscale cloud providers.
- Preferred computing agreements.
- Dedicated hardware. "We are seeing sustained interest from multiple parties," said Kramer. "Hardware will be sold and quantum will run on-premises."
- Apps and software.
Chapman added that there's a lot of interest in quantum networking and that has potential too. IonQ could also be involved with designing products with quantum systems. "At some point in the future, we'll be doing designs and getting royalties for things like battery design and drug discovery," said Chapman. "If 10- to 15-years from now our only source of revenue is systems sales we somehow failed."
Final thought. It's easy to argue that IonQ will simply be roadkill for much larger players including IBM, Google, Nvidia and a bevy of others. Then again, IonQ has a pragmatic approach and focus that potential rivals don't have. For now, track the quantum computing space in a future file.
Tech Optimization
Data to Decisions
Innovation & Product-led Growth
Quantum Computing
Chief Information Officer
Chief Technology Officer