Former Vice President and Principal Analyst
Constellation Research
Steve Wilson is former VP and Principal Analyst at Constellation Research, leading the business theme Digital Safety and Privacy. His coverage includes digital identity, data protection, data privacy, cryptography, and trust. His advisory services to CIOs, CISOs, CPOs and IT architects include identity product strategy, security practice benchmarking, Privacy by Design (PbD), privacy engineering and Privacy [or Data Protection] Impact Assessments (PIA, DPIA).
Coverage Areas:
- Identity management, frameworks & governance- Digital identity technologies- Privacy by Design
- Big Data; “Big Privacy”- Identity & privacy innovation
Previous experience:
Wilson has worked in ICT innovation, research, development and analysis for over 25 years. With double…...
After spending two years researching blockchain and the evolution of advanced ledger technologies, I still find a great spread of understanding across my clients and business at large about blockchain. While ledger superpowers like Hyperledger, IBM, Microsoft and R3 are emerging, there remains a long tail of startups trying to innovate on the first generation public blockchains. Most of the best-selling blockchain books confine themselves to Bitcoin, and extrapolate its apparent magic into a dizzying array of imagined use cases. And I’m continuously surprised to find people who are only just hearing about blockchain now.
For all sorts of specialists, it can seem that everyone is talking about blockchain and ledger technologies, but the truth is most people are not yet up to speed. No one should be shy to ask what blockchain is really all about.
Many blockchain primers and infographics dive into the cryptography, trying to explain to lay people how “consensus algorithms”, “hash functions” and digital signatures all work. In their enthusiasm, they can speed past the fundamental question of what blockchain was really designed to do. I’ve long been worried about a lack of critical thinking around blockchain and the activity it’s inspired. If you want to be able to pick the wheat from the chaff in this area, you really only need to know what blockchain does, and not how it does it.
So I’ve tried to write a fresh and uncomplicated explanation of what blockchain can do and what it cannot do. You can down load the report Blockchain Explained in Plain English here.
Former Vice President and Principal Analyst
Constellation Research
Doug Henschen is former Vice President and Principal Analyst where he focused on data-driven decision making. Henschen’s Data-to-Decisions research examines how organizations employ data analysis to reimagine their business models and gain a deeper understanding of their customers. Henschen's research acknowledges the fact that innovative applications of data analysis requires a multi-disciplinary approach starting with information and orchestration technologies, continuing through business intelligence, data-visualization, and analytics, and moving into NoSQL and big-data analysis, third-party data enrichment, and decision-management technologies.
Insight-driven business models are of interest to the entire C-suite, but most particularly chief executive officers, chief digital officers,…...
Teradata simplifies pricing, executes on business consulting and hybrid cloud strategy. A look at next steps in the company’s ongoing transition.
“Business outcome led, technology enabled.” This was the theme at the May 8-10 Teradata Third-Party Influencers Summit in San Diego, and it reflected a two-to-one ratio of consulting-oriented presentations to technology updates.
Teradata has been expanding already robust consulting and implementation offerings in part because mass migrations to cloud computing and open-source big data platforms like Hadoop have reduced demand for Teradata’s on-premises racks and appliances for data warehousing. Even as data volumes have continued to grow exponentially, Teradata’s revenues have declined in recent years from a high of $2.7 billion in 2014 to $2.3 billion in 2016.
Teradata compared it's old (at left) and new (at right) pricing scheme and cloud managed services options at its May Influencers Summit.
Last year’s Summit was held shortly after the company replaced its CEO, announced plans to sell off its Aprimo marketing business unit, and introduced a more aggressive path to cloud and consulting services. At this year’s Summit we learned that Teradata has not only executed on that strategy, it has gone further to transform itself by pursuing simplicity, flexibility and control in four areas:
Pricing: Responding to feedback that its licensing approach was too complex, with too many licensing models and too many a la carte options, Teradata has devised a consistent, subscription-based licensing approach that will apply on-premises or in private or public clouds. The model is based on two dimensions: T Cores and Tiers. T Cores measure compute cores and disk I/O, but there are discounts if you’re using less than maximum input/output capacity.
The four-tiers reflect how capacity is being used, ranging from the free Developer tier to progressively more feature-rich (and most costly) Base (simple production), Advanced (production with mixed workloads), and Enterprise (mission-critical, enterprise workloads) tiers. The pricing is designed to be simple, predictable and consistent, with no penalties for choosing or moving between on-premises, private cloud or public cloud deployment. What’s more, pricing is more aggressive, with the Base Tier taking on cloud rivals like Amazon Redshift.
Portfolio: Where Teradata previously offered as many as nine systems in its portfolio, in now offers just two. IntelliFlex, the company’s new flagship, separates storage and compute decisions to support multiple workloads within a single rack. Customers can add different types of storage and compute nodes, ranging from archival retrieval to the ultimate in in-memory query performance. Customers can also add capacity in smaller increments than previously available and they can quickly reconfigure as needs change.
IntelliBase is Teradata’s entry-level appliance. It costs approximately 15% more than commodity hardware. IntelliBase is designed for more balanced data warehouse workloads. IntelliBase is designed for more balanced data warehouse workloads. It is not as flexible as IntelliFlex, which can be reconfigured to address high I/O or high CPU requirements..
Cloud: Teradata has made over and recast its managed cloud services as IntelliCloud. The offering combines the new T-Core- and Tier-based pricing scheme with three flexible infrastructure options behind the cloud services. Teradata previously offered only appliance-grade (2800 series) capacity behind its services, but you can now choose IntelliFlex or IntelliBase as the platform for managed services in the Teradata Cloud, which has data centers in Las Vegas and Frankfurt. The third option is Teradata-managed services running on carefully selected infrastructure services in the Amazon cloud (and, later this year, the Microsoft’s Azure cloud). Consumption options are more elastic with the public cloud options, but it won’t be as performant as IntelliFlex-based capacity, and service-level agreements aren’t available because Teradata has no control over the infrastructure. The intent it to give customers choice, with a fourth choice being bring-your-own-license and managing Teradata Database on AWS or Azure yourself.
Consulting: Teradata has consolidated its growing consulting offerings under the Teradata Global Services umbrella, and it has formalized three service lines to avoid overlaps and confusion. Think Big Analytics, the big data consulting business Teradata acquired in 2014, continues as the business-outcome-focused unit, offering industry-focused expertise in data science, data visualization and big data solutions. Enterprise Data Consulting focuses on technology, offering expertise in architecture, data management, data governance, security and services. Customer Services helps customers get the most out of their systems and people, applying proactive and reactive expertise in systems and software management and change management.
MyPOV on Teradata’s Ongoing Transformation
Disruptive market forces have dealt Teradata a tough hand to play. There’s clearly disillusionment with complex open source platforms like Hadoop these days, but that doesn’t mean we’re going back to Teradata’s heyday of enterprise data warehousing. Companies are still pursuing high-scale data lake approaches on low-cost, distributed platforms, whatever flavor prevails (whether that’s HDFS, objects stores like S3 and Azure Data Lake, or the next open source fad). Companies will also continue to rationalize their comparatively high-cost data warehousing infrastructure expenditures.
Teradata acknowledged last year that we’re in a “post-relational world,” but this year’s Summit shows signs that it’s truly adapting to a changed market. The company has not only delivered far more flexible hardware, it has gone further with the simplified, hybrid subscription-based pricing and more flexible cloud-deployment options.
Teradata is becoming more of a software and services company and less of a hardware vendor. That shift should eventually improve profitability, even if revenues continue to slide as deployments shift to the cloud.
Will customers trust Teradata to provide impartial, “business outcome led” consulting services? Customer Gerhard Kress said he chose Teradata in 2013 in large part because “the company understands that the world is a lot bigger than Teradata.” Director, Data Services at Siemens, Kress presented at the Summit on the train manufacturer’s global IoT deployment, and he noted that other vendors (mostly big platform vendors) asserted that they could address all challenges within their stacks. Teradata, meanwhile, suggested a heterogeneous approach reflecting technologies already in place at Siemens.
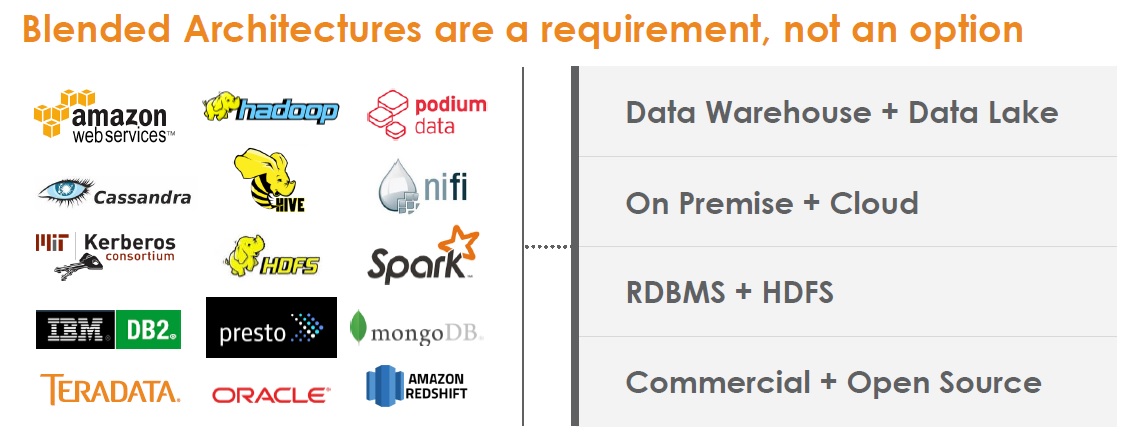
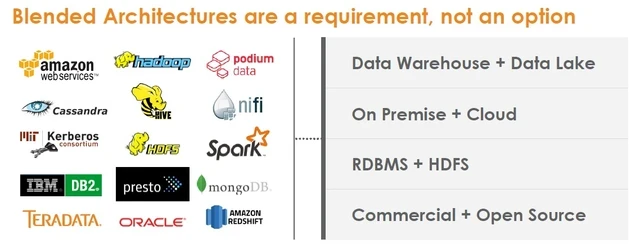
This “Blended Architecture” slide, from a Teradata Ecosystem Architecture Services presentation,
captures the vendor’s realistic sense of its place within enterprise environments.
Teradata has also become more realistic about its cloud ambitions. Two years ago Teradata talked about pursuing midsize businesses with the Teradata Database on AWS service. At this year’s Summit Teradata said it’s no longer pursuing that idea. Instead, executives said the company is focused on the needs of the 500 highest-scale and most sophisticated customers. That’s where Teradata’s technology really shines.
Teradata thrived in the past when it focused on delivering data-driven business outcomes at top of the market. It appears that focus is back.
Chris Kanaracus is managing editor of Constellation Insights.
Insights delivers exclusive, daily analysis of breaking news across Constellation’s eight business research themes to Constellation Executive Network members.
Prior to joining Constellation, Kanaracus spent seven years covering the enterprise software industry for IDG News Service, where he frequently broke exclusive stories with a focus on end-customer issues. Kanaracus has also held various managerial and reporting roles at newspapers in New England since 1998.
Twitter: @chriskanaracus
, Title: Big IdeasConstellation Insights
Insights delivers exclusive, daily analysis of breaking news across Constellation’s eight business research themes to Constellation Executive Network members.
...
Vice President and Principal Analyst, Constellation Research
Constellation Research
Andy Mulholland is Vice President and Principal Analyst focusing on cloud business models. Formerly the Global Chief Technology Officer for the Capgemini Group from 2001 to 2011, Mulholland successfully led the organization through a period of mass disruption. Mulholland brings this experience to Constellation’s clients seeking to understand how Digital Business models will be built and deployed in conjunction with existing IT systems.
Coverage Areas
Consumerization of IT & The New C-Suite: BYOD,
Internet of Things, IoT, technology and business use
Previous experience:
Mulholland co authored four major books that chronicled the change and its impact on Enterprises starting in 2006 with the well-recognised book ‘Mashup Corporations’ with Chris Thomas of Intel. This was followed in…...
In January, SAP moved to bundle its offerings for IoT under the brand name Leonardo. Jump forward just several months later to this week's Sapphire Now conference, and the vision has already grown much broader.
What you might call 'Leonardo 2.0' now encompasses IoT, machine learning, analytics, big data, design thinking services and blockchain, all built atop SAP's cloud platform. Customers who adopt SAP Cloud Platform won't be tied to SAP data centers for the underlying infrastructure, as the company has inked partnerships with Amazon Web Services, Microsoft Azure and Google Cloud Platform as well.
The new Leonardo is SAP's "digital innovation system," and the basis for the company's drive into digital transformation projects. Digital transformation was the central theme of this year's Sapphire, and where SAP sees ample opportunity for growth as customers not only migrate older ERP environments to the new S/4HANA, but look to adopt the leading-edge technologies targeted by Leonardo.
SAP is shipping a number of industry accelerators—fixed-priced products composed of services and subscription licenses—for Leonardo, aimed initially at retail, sports organizations, consumer products and discrete manufacturing.
For sure, Leonardo is an apt title for what the product set stands to offer customers, with its evocation of renaissance man Leonardo Da Vinci. It also raises the bar high for SAP to deliver customer success, of course, given how much Leonardo projects will depend not only on technology but professional services from SAP and partners.
Some may question whether quickly broadening Leonardo's remit so far beyond IoT could create market confusion, but Sapphire provides the biggest platform of the year for SAP to educate customers on its product strategy. In any event, it's far from clear how much penetration the original Leonardo vision had made among the installed base.
"There will be a lot of CIOs who will be grateful for the clarity this new version of SAP Leonardo provides towards potential a proof-of-concept deployment of IoT and AI in the enterprise," he says. "Describing SAP Leonardo as adding systems of intelligence to to the traditional SAP systems of record will help the general market confusion as to exactly how to view the role of IoT and AI in enterprise digital business, as well as positioning Leonardo as an architecrure and a platform for ongoing development."
"The numbers and importance of the partners who have expressed commitment to supporting SAP Leonardo suggests that they too feel this is an important and radical move in the marketplace," Mulholland adds. "Constellation Research advises SAP customers to take a detailed look, and suggests non-SAP customers may also find the platform interesting too."
24/7 Access to Constellation Insights Subscribe today for unrestricted access to expert analyst views on breaking news.
Chris Kanaracus is managing editor of Constellation Insights.
Insights delivers exclusive, daily analysis of breaking news across Constellation’s eight business research themes to Constellation Executive Network members.
Prior to joining Constellation, Kanaracus spent seven years covering the enterprise software industry for IDG News Service, where he frequently broke exclusive stories with a focus on end-customer issues. Kanaracus has also held various managerial and reporting roles at newspapers in New England since 1998.
Twitter: @chriskanaracus
, Title: Big IdeasConstellation Insights
Insights delivers exclusive, daily analysis of breaking news across Constellation’s eight business research themes to Constellation Executive Network members.
...
SAP CEO Bill McDermott took the stage for the Sapphire Now conference's opening keynote this week, and after a few minutes of audience engagement and banter, launched into his first core topic. No, it wasn't about a new product or strategy, but rather something that affects many SAP customers: Indirect access.
The term refers to scenarios in which a customer uses a third-party application, such as Salesforce, to tap into SAP system data. The problem arises when a user doing so isn't also a licensed SAP user. In the course of a software license audit, companies can find themselves on the hook for substantial penalties for unpaid license fees, whether the violation was intentional or not.
Earlier this year, SAP won a landmark court victory against drinks distributor Diageo, who could pay up to $68 million in penalties. Diageo had developed two Salesforce-based systems which it connected to its core SAP system through SAP Process Integration. The court rejected Diageo's defense that PI served as a "gatekeeper" license to SAP.
SAP has also sued Anheuser-Busch InBev, the world's largest brewer, regarding both alleged indirect access violation and unlicensed use of SAP software. It is seeking $600 million.
Invoking the notion of "empathy" toward SAP customers—a theme he first introduced at last year's Sapphire—McDermott referred to the indirect access issue and said SAP had come up with "simplified pricing," which he briefly described.
"Procure-to-pay and order-to-cash scenarios will now be based on orders, which is a measurable business outcome for any business," McDermott said. The more significant statement came next. "In addition, static read access in third-party systems is your data," McDermott said. "Competitors charge you for static read in third-party systems, SAP will not."
SAP corporate development officer Hala Zeine elaborated on the topic in a blog post. During discussions over pricing and licensing with user groups, indirect access came up repeatedly, Zeine wrote:
We decided to tackle this topic first through the lens of pricing modernization. Our objective was to make pricing predictable, linked to unit of value, transparent, and consistently applied.
We looked first at the areas that would have the greatest impact on the greatest number of people. We found that approximately 80 percent of our ERP customers will benefit from our changes to just these three scenarios: Procure-to-Pay, Order-to-Cash, and Indirect Static Read.
Indirect static read access reinforces that a customer’s data is yours. Just because the data was in the SAP system, does not mean you should pay to view it when it is outside the SAP system. Indirect static read is read-only that is not related to a real-time system inquiry or request and requires no processing or computing in SAP system. Indirect Static Read will now be included in the underlying software license – i.e. free of additional charge when a customer is otherwise properly licensed. SAP leads the pack in addressing customer expectations related to this scenario.
Does this address every indirect access scenario in the age of devices, IoT, and collaborative networks? Not yet. There is much more to do and we are eager to keep updating pricing scenarios to bring you greater value. It is, however, a step in the right direct toward pricing modernization.
However, SAP in turn wants customers to help avoid an unpleasant audit experience by proactively examining their current landscapes and usage:
If you’re fully licensed, there’s no action for you. However, if you’re questioning whether you are under- licensed, let’s talk about it. ... SAP assures customers who proactively engage with SAP to resolve such under-licensing of SAP software that we will not collect back maintenance payments for such under-licensing. We will look at your specific circumstances when resetting your licensing agreement, including providing you the opportunity to receive credit for certain products you may have already licensed so you can update to the new metrics.
Analysis: A Measured Step In SAP Customers' Favor
The UK ruling against Diageo should have been a wakeup call for any SAP customer using third-party software in conjunction with it—which is obviously a large percentage of the overall base. SAP's case against Anheuser-Busch InBev is in arbitration, meaning the details—in particular, any defenses the brewer may have—won't become public.
While SAP is offering back maintenance indemnity for under-licensed customers who come forward willingly, doing so could still result in additional license fees, which then carry maintenance going forward. There's no sound argument to be made for willingly using SAP software without required licenses, but it remains to be seen how many customers take SAP up on its offer. In any case, Constellation has seen a significant uptick of late in inquiries regarding indirect access and related SAP license audits—in short, this issue is not going away.
Meanwhile, the concession SAP offered on indirect access is limited in scope. Indirect static read means just that—nothing that requires processing within the SAP system. Still, indirect static reads are part of many valuable use cases.
Constellation backs the generally accepted industry parameters of indirect access, which should include the ability to process batch data; aggregate information into a data warehouse or other data store; access data for use in another system via data integration; and to enter data from a third party system. On its face, SAP's new policy would only prohibit the last.
However, another telling passage in Heine's statement was this:
Does this address every indirect access scenario in the age of devices, IoT, and collaborative networks? Not yet. There is much more to do and we are eager to keep updating pricing scenarios to bring you greater value.
That's a bit opaque, considering how important those workloads are now and will be in the future. Digital transformation is the predominant theme of this year's Sapphire event, which featured the unveiling of an expanded product strategy called Leonardo, a "digital innovation system" that brings together machine learning, IoT, blockchain and other leading-edge technologies on SAP's cloud platform.
SAP, of course, sees digital transformation projects as its major growth engine and wants customers to come along for the ride quickly. To that end, it will hopefully provide a broader explanation of how indirect access will work in this new landscape soon, preferably before the next Sapphire rolls around. That would be the empathetic thing to do.
24/7 Access to Constellation Insights Subscribe today for unrestricted access to expert analyst views on breaking news.
Chris Kanaracus is managing editor of Constellation Insights.
Insights delivers exclusive, daily analysis of breaking news across Constellation’s eight business research themes to Constellation Executive Network members.
Prior to joining Constellation, Kanaracus spent seven years covering the enterprise software industry for IDG News Service, where he frequently broke exclusive stories with a focus on end-customer issues. Kanaracus has also held various managerial and reporting roles at newspapers in New England since 1998.
Twitter: @chriskanaracus
, Title: Big IdeasConstellation Insights
Insights delivers exclusive, daily analysis of breaking news across Constellation’s eight business research themes to Constellation Executive Network members.
...
Principal Analyst and Founder
Constellation Research
R “Ray” Wang is the CEO of Silicon Valley-based Constellation Research Inc. He co-hosts DisrupTV, a weekly enterprise tech and leadership webcast that averages 50,000 views per episode and blogs at www.raywang.org. His ground-breaking best-selling book on digital transformation, Disrupting Digital Business, was published by Harvard Business Review Press in 2015. Ray's new book about Digital Giants and the future of business, titled, Everybody Wants to Rule The World was released in July 2021. Wang is well-quoted and frequently interviewed by media outlets such as the Wall Street Journal, Fox Business, CNBC, Yahoo Finance, Cheddar, and Bloomberg.
Short Bio
R “Ray” Wang (pronounced WAHNG) is the Founder, Chairman, and Principal Analyst of Silicon Valley-based Constellation Research Inc. He…...
Independent enterprise software support provider Rimini Street will soon be a publicly traded company, but via a merger and not with a long-expected initial public offering. The move stands to give Rimini the capital it needs for expansion.
Under the arrangement, Rimini Street will merge with GP Investments Acquistion Corp. The latter will be renamed Rimini Street and continue trading on NASDAQ, but with the ticker symbol RMNI. The deal will have an initial enterprise value of $837 million. Rimini Street founder and CEO Seth Ravin, who will lead the combined company, laid out the rationale for the deal in a statement:
"The combination with GPIAC will provide Rimini Street additional growth capital to expand service offerings and capabilities, strengthen our balance sheet and fund potential acquisitions," said Mr. Ravin. "We believe that having a public company structure will further fuel our growth by facilitating additional sales opportunities and providing additional capital market access."
Rimini is the most prominent third-party support vendor in the market. Founded in 2005, the company has offered software support for Oracle, SAP and other products at half the price of vendor-provided maintenance, while claiming superior service.
It has experienced steady growth even while battling litigation brought against it by Oracle, which alleges Rimini's business model infringed on its intellectual property. That case, as well a suit Rimini filed against Oracle aren't yet resolved, but the specter of litigation apparently wasn't a deal-breaker for GPIAC. (Nor has it been for customers, given Rimini's advancement in the market).
Third-party maintenance appeals to customers with stable systems and little desire to upgrade to newer versions as vendors release them. The option has long been a pillar of Constellation Research's Software Bill of Rights.
While Rimini has reported annual run-rate revenue of $196 million, that remains a tiny fraction of the total addressable market for on-premise maintenance, which the company estimates at $81 billion.
"I think this [merger] gives Rimini a huge opportunity to expand," says Constellation Research founder and CEO R "Ray" Wang. "More importantly, they can increase their speed in go-to-market."
Rimini's emergence as a public company could have a ripple effect, emboldening more players to enter the business, while prompting competitive responses from incumbent software vendors. Overall, the move looks like a good one not only for Rimini, but enterprise software customers.
24/7 Access to Constellation Insights Subscribe today for unrestricted access to expert analyst views on breaking news.
Sales & marketing veteran with almost 30 years’ experience and now 1800 digital projects to his credit for clients including Morgan Stanley, AOL, Hyatt Gaming Management, Snyder's of Hanover, Hitachi, the Home Depot, Kraft Foods, Drees Homes, American Idol, and hundreds more, including leading agencies around the North America.
...
Great customer service goes beyond fixing a computer or handing out discounts.
It’s about leaving people with a good feeling about your business.
And thanks to social media, your customers and prospects are already sharing thoughts about your brand whether you like it or not.
So if you want to minimize the negativity and amplify the positivity, here’s ten simple tips:
1. Treat your employees as your first customer
Great customer service and experience starts with those delivering it: your employees.
When employees are happy, so will your customers.
Southwest Airlines has been consistently ranked as one of the best places to work as they built a work culture of putting their employees first.
The airline company has a team-based environment, one that is fun and inclusive with core values that remind their employees to enjoy their work.
They motivate employees to take pride in the work they do, which often leads long lasting customer service experiences.
A famous example of how Southwest Airlines went above and beyond for their customers occurred in 2011. A man booked a last minute flight to Denver in order see his 3 year-old grandson one last time. Due to heavy traffic, he arrived at the airport 12 minutes after the plane was scheduled to leave, but the pilot had specifically waited for him before taking off.
Go the extra mile for your employees, and they’ll go the extra mile for you.
2. Build an emotional connection with customers
The most memorable customer experiences are the ones that create an emotional connection with customers.
A great example comes from Zappos, the popular online shoe store.
A customer was late returning a pair of shoes due to a death in the family, so the Zappos’ customer service team went out of their way to take care of the return shipping and arranged a courier to pick up the shoes at no cost. They also sent the customer a bouquet and a note offering their condolences.
That’s service with a human touch.
So how do you create customer connections?
It starts with listening.
The process of listening itself shows customers that you care, and you’ll also be able to uncover their needs, challenges, and pain points.
Use tools like Hootsuite, Twitter hashtags, or SocialMention.com to monitor conversations people are having about your brand.
3. Get real (time) about feedback
The best way to capture customer feedback is right after you deliver it.
Consider post-interaction surveys that can be delivered in real-time through programmed tools such as email or phone calls.
Starbucks, for example, often sends an email survey to their customers immediately after a store visit.
The survey asks customer service questions specifically for the Starbucks location they had just made a purchase. In the survey, they ask the customer to rank the friendliness of the baristas and speed of the service.
AT&T uses SMS or text messaging to send a customer service survey to gather feedback from their customers after visiting their stores.
Don’t forget to link great customer feedback to specific customer support teams, as recognizing their contributions helps demonstrate what quality service looks like to other employees.
4. Focus furiously on individual customer needs
A great customer service strategy always starts with understanding what your customer needs.
And if you really want to know what they need, just ask them.
Take Feargal Quinn, the founder and president of Irish food distributor SuperValu. He personally invites twelve customers to join him in a roundtable discussion twice a month.
He asks them about service levels, pricing, product quality, and even about upcoming advertising promotions.
Quinn uses the feedback to evaluate store managers and to improve the company’s strategic planning, and so far it’s working.
5. Practice Social Listening
What’s the best tool to improve customer experience?
Your ears, for listening.
You can create wonderful customer experiences just by listening on social media.
One example comes from Tommee Tippee cups.
By listening on Twitter, the company came across a father who needed replacement of a limited edition Tommee Tippee sippy cup for his son, Ben Carter, who has severe autism.
These sippy cups were the only cups Ben would drink from.
So the father created a hashtag called #cupsforBen and the tweet went viral, garnering hundreds of thousands of retweets, likes, and shoutouts.
As a result, Tommee Tippee announced they would create a limited run of 500 of the discontinued cups, especially for Ben.
That’s how to turn listening into memorable customer service experiences.
There’s lots of tools for social listening such as Hootsuite, Quora, Reddit, SocialMention.com, or just simply searching with hashtags, brand terms, or relevant keywords.
Social media isn’t all about promoting – it’s about listening and helping.
6. Use AI to your advantage
We all know about the importance of customer data.
But there’s different ways of getting it than with surveys, feedback forms, and questionnaires.
In fact, with AI there are ways of gathering customer intelligence without even lifting a finger.
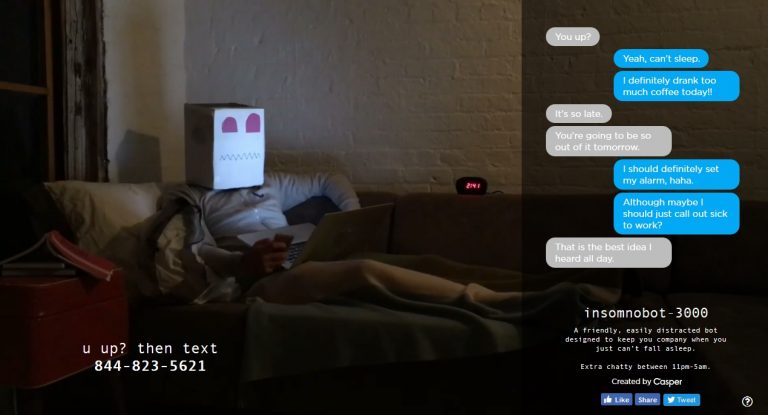
To use it, customers simply text “Insomnobot3000” from their mobile phones and talk about whatever is on their mind and it will have a real conversation with you.
With the Insomnobot3000, Casper is able to collect mobile numbers and send insomniacs promotional offers and discounts for their comfy mattresses. Casper pulled in $100 million in sales its first year of launching the chatbot.
Other examples include Netflix, who use predictive analytics to provide show recommendations to their subscribers, and Google, who use AI to help redirect drivers around traffic jams.
7. Prove that you really, really appreciate your customers
People want to feel that the companies they interact with appreciate their business.
TD Bank created one of the most memorable customer appreciation campaigns. What was so memorable about it, you ask?
They gave away cold, hard, cash.
Nothing says thank you like giving away money.
But it’s not always about money.
In their latest campaign, TD created “TD Thank You Account” where they surprised millions of their North American customers at ATMs, in branches and on the phone with personalized messages of thanks and touching gifts.
A woman from Drayton Valley, Alberta, who was diagnosed with cancer, received a special vacation getaway to Jasper with her family.
When AT&T reached two million fans on Facebook, they thanked their fans by making over 2,000 personalized “thank you” videos. Instead of using boring generic social media updates, you can get creative with showing appreciation to your customers.
8. Livin’ things up with live chat
Live chat technology has been around for a while, but businesses have been slow to adopt it into their customer service strategy.
But live chat is crucial, because customers demand immediate responses when it comes to customer service.
They want answers now, not later today or tomorrow.
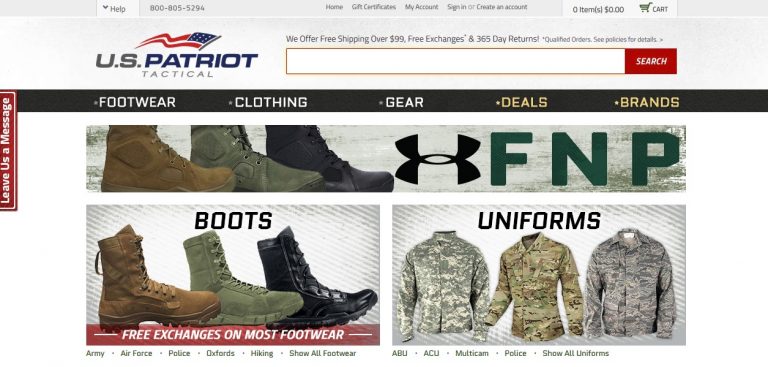
One company that makes great use of live chat technology is U.S. Patriot Tactical.
The company uses SMS to Chat services that allow customers to start a live chat with their support team with a simple text message.
They display their “Text-to-Chat” phone number on their website in order to quickly ease communication around order inquiries, status and returns.
9. Speak human
Tech-speak, legal-speak, jargon-speak.
Throw it all out the window when it comes to customer communication.
Health insurance, for example, is one of the most complex things that we need to buy: the language, policies, and coverage can be beyond confusing.
That’s why Oscar, a health insurance company from New York uses a simplified design website experience and easy to understand language to “speak human” to customers, and help them find a policy that works best for them.
They do this by asking simple questions like “How many doctor visits per year will you need?” and excluding words like premiums and deductibles.
Oscar was able to get 16,000 people to say yes to their plan selections and buying process in their first year.
That’s success any human can understand.
10. Encourage engagement
The quickest path to a better customer experience is engagement, engagement, engagement.
You need to create customer interactions that produce engagement.
Example Microsoft.
Microsoft has a strong presence on Twitter, with a dedicated Twitter account to numerous themes including security, development, events, careers and customer service.
By covering all areas, Microsoft customers can interact and engage with every aspect of the brand.
The various Twitter channels all serve a different purpose but what underlines them all is engagement.
Other ways you can encourage engagement is by simply asking questions to start conversations, take quick polls, ask for feedback, and comment on other blogs, chats, and forums.
Or, you can curate content from your followers.
Share user generated content such as photos or videos of your products through contests or other incentives.
Respond to your comments in a timely manner on social media. When you respond quickly, customers are more likely to feel that your business values their feedback and will remember your response.
Burt’s Bee’s regularly responds to comments and questions on Facebook within minutes to an hour. They have more than 2.8 million followers on Facebook and responses are signed by individual employees to build trust and improve transparency.
Chris Kanaracus is managing editor of Constellation Insights.
Insights delivers exclusive, daily analysis of breaking news across Constellation’s eight business research themes to Constellation Executive Network members.
Prior to joining Constellation, Kanaracus spent seven years covering the enterprise software industry for IDG News Service, where he frequently broke exclusive stories with a focus on end-customer issues. Kanaracus has also held various managerial and reporting roles at newspapers in New England since 1998.
Twitter: @chriskanaracus
, Title: Big IdeasConstellation Insights
Insights delivers exclusive, daily analysis of breaking news across Constellation’s eight business research themes to Constellation Executive Network members.
...
SAP is getting its app store act together, with the unveiling of a new App Center that brings together partner offerings for its entire catalog in the same place. The move gets what had become a growing problem with app store sprawl under control, as SAP's Steve Ache writes in a blog post:
In the first generation of the SAP App Center we focused on applications that were designed to run on SAP Cloud Platform. The SAP App Center developed into great resource for customers who were looking for applications to extend their digital core.
At the same time, SAP continued to run other marketplaces, particularly those that are associated with our cloud applications like – SAP SuccessFactors, SAP Analytics, Concur, SAP Ariba, and others. The marketplaces continued to grow, and we uncovered a problem. We had partners who developed applications that had to list and maintain their applications on multiple marketplaces. And we had customers who had to visit multiple SAP marketplaces to find what they were looking for.
SAP's first move was to consolidate the SuccessFactors app store into App Center last year. The latest iteration of App Center goes much further, bringing together all partner applications. There are now 1,405 applications in total on the site, the vast majority of which were developed by partners. It also features Ariba technology for payments, along with billing and provisioning capabilities.
Meanwhile, SAP Store will remain in place for software and services sold by SAP directly.
Analysis: One-Stop Shopping Makes Good Sense
It's good to see SAP recognize the problem that had formed due to multiple app stores, and the move to consolidate them is one that should especially please partners, who will benefit from greater visibility compared to what was possible in the previous siloed structure.
The combined store should also appeal to customers thanks to the improved navigation and buying experience—in particular the benefit to procurement of having purchasing, billing and partner vendor communications through a single portal.
It also represents an example of SAP living up to its pledge in recent years to become easier to work with on both a partner and customer front. That being said, the standard in enterprise app stores has long been set by Salesforce's AppExchange, which has been unified from the beginning and remained so through dozens of acquisitions. In that sense, SAP's new App Center is playing catchup, but it's still a welcome, if overdue move.
24/7 Access to Constellation Insights Subscribe today for unrestricted access to expert analyst views on breaking news.
Chris Kanaracus is managing editor of Constellation Insights.
Insights delivers exclusive, daily analysis of breaking news across Constellation’s eight business research themes to Constellation Executive Network members.
Prior to joining Constellation, Kanaracus spent seven years covering the enterprise software industry for IDG News Service, where he frequently broke exclusive stories with a focus on end-customer issues. Kanaracus has also held various managerial and reporting roles at newspapers in New England since 1998.
Twitter: @chriskanaracus
, Title: Big IdeasConstellation Insights
Insights delivers exclusive, daily analysis of breaking news across Constellation’s eight business research themes to Constellation Executive Network members.
...
Vice President and Principal Analyst
Constellation Research
Holger Mueller is VP and Principal Analyst for Constellation Research for the fundamental enablers of the cloud, IaaS, PaaS and next generation Applications, with forays up the tech stack into BigData and Analytics, HR Tech, and sometimes SaaS. Holger provides strategy and counsel to key clients, including Chief Information Officers, Chief Technology Officers, Chief Product Officers, Chief HR Officers, investment analysts, venture capitalists, sell-side firms, and technology buyers.
Coverage Areas:
Future of Work
Tech Optimization & Innovation
Background:
Before joining Constellation Research, Mueller was VP of Products for NorthgateArinso, a KKR company. There, he led the transformation of products to the cloud and laid the foundation for new Business Process as a…...
SAP is planning to make major additional investments in Business ByDesign, the cloud ERP suite it first launched in 2007, hoping to make the product finally reach the critical mass it originally expected.
Business ByDesign has had quite a history. Developed at high cost, it was first launched with much ado in 2007 as the company's entry into cloud-based ERP, and at the time, company officials expected it to have 10,000 customers by 2010 and be generating $1.4 billion in revenue.
Needless to say, those lofty goals weren't met. One reason was the initial architectural choice, which didn't scale in a cost-efficient manner. SAP pulled back on the ByDesign rollout in order to re-architect it for true multitenancy.
Other problems were internal. Some of SAP's sales force wasn't keen on pushing the new, untested solution to customers and prospects, fearful it would cut into sales of established products such as Business One and Business All-in-One, which carried more lucrative commissions.
By the same token, ByDesign suffered from an identity crisis, as SAP struggled to clearly define and differentiate it from those other ERP suites, which like ByDesign are aimed at small and medium-sized companies.
In subsequent years, ByDesign was the subject of repeated rumors of its demise, ones SAP consistently denied. It continued to develop the product and it is now used by customers in 120 countries. Sales were up 43 percent year-over-year in the first quarter for "new and upsold bookings," SAP said in a statement.
The customer count for ByDesign is now closing in on 4,000. While far short and past SAP's original hopes, that figure is not insignificant, and one SAP believes it can now scale more rapidly:
SAP has goals to significantly increase SAP Business ByDesign development resources, ramp up marketing spend by 10X to deliver demand to partners so partners can focus on differentiating their offerings, and aggressively raise partner capacity with a firm commitment to achieving growth goals.
“SAP Business ByDesign is SAP’s lead offering for mid-market customers. Our customers often share how the solution enables them to run more effectively as they grow and thrive,” said Robert Enslin, president of the Cloud Business Group, SAP.
Enslin's description of ByDesign as SAP's "lead" option for the midmarket is no accident. While it falls in line with the company's overall cloud-first strategy, that type of wording is a far cry from ByDesign's years in the wilderness, when it received little public mention from SAP officials.
In one sense, the new investment in ByDesign isn't a surprise, since SAP needs a cloud ERP for the SMB space, says Constellation Research VP and principal analyst Holger Mueller.
S/4HANA, the successor to SAP Business Suite, isn't ready to serve the needs of both large enterprises—its core market—and SMBs, although that is the eventual goal, he notes. "No ERP vendor has spanned large and SMB enterprise with the same product," he says. "It won't happen right now either, especially with Oracle buying NetSuite and running on two platforms."
24/7 Access to Constellation Insights Subscribe today for unrestricted access to expert analyst views on breaking news.
My Perspective: Back in the 1980s I took a couple of classes in neural networks. It was, at the time, the logical continuation of my interest in AI: we had little machine power, but we had C and Pascal (not to mention FORT and Assembler) and that was going to be enough. The first course was a three months jaunt into building a neural network that could recognize any letter in in the alphabet by either hearing the sound or looking at a printout/drawing of it. This is 1986-87. It was fun, but it also introduced me to the complexity of a neural network and how we actually have to teach computers.
I found the above article while going through rabbit holes on AI a few months ago, and I really liked it because it does a great job of simplifying that first foray into neural networks (which we use, in different forms, for machine learning and “deep learning” (marketing name for machine learning)). It covers what for me became the next long search: to understand cognition and learning (still don’t get the most advanced concepts, but it’s a fascinating hobby and science).
I am hoping that by reading it and mixing it with my previous link on ML, you begin to both see the potential and complexity behind ML (and realize that for most vendors today, it’s just another marketing term).
disclaimers: this sh— stuff is hard AF, but the easy part is to understand how and what cognition works. when i say most vendors are hyping and marketing, i mean no particular vendor — and of course, none of my clients — but a generalized statement considering the complexity and, still, academic nature of true ML. that first course i took? we barely made it past helping the machine learn both what a B was and how to recognize it. today you can get that in an open source library, at worst. c'est comment la vie avance…
A knowledge summary is a semi-long to a long post that synthesizes positions, concepts, and lessons learned around a topic. They consist of a mix of primary research with ideas and frameworks I built based on conversations and working sessions.
This knowledge summary will focus on concepts you have to know to succumb to embrace digital transformation in the next decade.
The problem is that digital has become the new crutch word much like e-anything or i-anything became the crutch letter in the late 1990s. And we have seen decent value arise from that use: iPhone and eCommerce are the two most recognized iconic words (and concepts).
The purpose of Digital is to replace all that has to do with computer-driven or computer-assisted. We have had computers since the 1980s in the organization, we cannot say “computer-driven transformation” as that ship has already sailed; we talk about digital as if it was a magical, mythical approach to changing things.
But it’s not.
At the core, this machine-driven revolution is different from the one 30+ years ago in what is focused on – data. That’s it, as simple as it can get. This transformation is about data.
It would be more appropriate to say it was about information (a combination of data, content, and knowledge that enables companies to solve problems better in context), but — as I said before… i-anything was already taken.
Seriously, it’s not about data only, it could never be.
Data is the representation of an event. What happened to whom or which, when, how, and where – it’s the pieces of information you need to recreate something: a customer signed up for a newsletter (what), they received the newsletter (what, when), they opened three of the five links (what, when, which), they did a search for further information (what, how, when), they bought a product (what, how, when, where), we shipped it (what, when, where, how), they received it (what, when).
That’s all data – every piece of that.
Data does not mean much without the other two parts of information: content and knowledge.
Content is the static information we (or someone else, if we believe in communities) created that describes an entity (product, solution, use cases, manuals, etc.). For example, the customer got a newsletter with content – information about products, services, discounts, coupons, etc. and acted on that. The data about the newsletter being distributed and the action remains, but without the content, we would not know why the client acted and we couldn’t track specific actions they took.
And that brings the final piece: knowledge. Knowledge, if you follow my writings, is wisdom – the applied, contextual, intent-driven use of content.
And that is where the reality of what data can do comes together — if you combine data about events with content related to that event and intent and context in the form of knowledge – what do you have? the right information, at the right time, in the right place personalized for each person, optimized for each situation, and outcome-focused.
Now you know what digital is and why it’s the source for business transformation this time around: even though data has been around from the beginning, it’s the leveraging of data mixed with the right content and knowledge, yielding information, that makes it the basis for this new evolution.
How do you use it?
There are two slides that I use to show my clients and people I talk to where / how / why information is to use it. First, where does information come from? Big Data — rather Big Noise.
Check it out…
The concept of Big Data is a misnomer: how can something be “data” or be anything if we don’t even know what it is. If one trillion IoT devices generate measurements, which ones are truly data and which ones are noise? If there are 20 millions tweets in one week mentioning your company name, product name, or someone in the company directly by name, how do you know which ones to reply to directly and which ones to safely ignore? What about corrupt or misspelled or damaged “data”? it’s not data until you structure it, until then is noise – simple.
Although the first reaction is always to store everything and “later we will figure it out” the volumes are becoming too large for that, and the need to use the data (and the speed at which data usability and usefulness decay) increases dramatically every day. Storing for future use is no longer possible these days. The next step is to filter the noise and create a signal. If a plane that uses Rolls Royce engines generates over a terabyte of data per flight, and there are thousands of flights daily worldwide – which piece of “data” should be stored? used? discarded? Filters make that decision.
Once the filters take their turn and the noise is selected as valuable, then we structure the information. This is the decision as to what it is: data, content, or knowledge? This is the moment the noise becomes structured and ready to be acted on. The concept of digital transformation being about acting on unstructured data is another misnomer – how can something be acted on if we don’t know what it is? where it came from? what is used for? once we filter the noise (create a signal) then we figure out what it is that we have, structure it, and store it in the proper place (or not, but that’s another post) and act on it.
These actions, the analytics or workflows applied to them, generate an insight – a something we did not know. These insights are what we use to make decisions, to act, or simply to inform – via dashboards and reports. These signals are also the components of information that will be used to power algorithms and AI components – and that will become the new filters for Big Noise. The cycle of optimization based on what we know and what we learned is then complete and we have both insights we didn’t before, and data (and content and knowledge) stored.
Very different from simply capturing everything to figure out later what to do, no?
Being Digital
This section is the second framework I use with clients and in conversations when talking about what it takes to become a digital enterprise. I must confess, this is not a new model – I first introduced it in 2013 – but have been working and optimizing it since. Thanks to all of you that helped me along the way.
Once you get past the awesomely-designed majestic use of colors and boxes, you end up with six components you can focus on: four yellow boxes, and two blue boxes. I know, mind-blowing.
The yellow boxes represent infrastructure, the purview of IT and Architects in your organization. As your organization becomes more entrenched in the cloud (which by now is commoditized, so I am assuming you are either already there or on your way there) they will notice more and more a need to structure their approach. The yellow boxes separate the different pieces they need to focus on:
cloud infrastructure, the core components used to run and interconnect everything
legacy access, because I am still proud of the code I wrote in the 1980s in COBOL and to be fair – a large number of you still use it and need it to run your organizations
interface connectivity, because in the age or mobile and IoT there is no longer a requirement but actually a necessity to be device-independent — this is not mobile-first, this is mobile-also
and to accommodate the hype of the day – AI (or advanced analytics, if you read my writings on the topic) with three specific outcomes: optimization, personalization, and automation.
I wrote about this framework before, the link is above and there is an update to it here as well, which is why I am just summarizing it here. If you need more details read those posts, or contact me.
Once you configure your distributed computing architecture (AKA cloud) to operate in a model similar or comparable to the above, you will end up with two blue boxes – which is where the magic behind digital business transformation happens.
The information blue box is what we were discussing above in the previous section: how to find the right data, content, and knowledge to create the necessary information for every transaction. The information will come from anywhere: devices, legacy data or applications, or AI and analytics engines. The role of the information layer is to make sure that all information is considered, and the best selected, when crafting the response to an interaction.
The experience layer is the one where most organizations would love to have control – but they can’t. The concept of building experiences for customers is archaic and, frankly, dumb. This is not about understanding customers journeys or planning for them – or anything like that. This is about understanding that stakeholders (notice it says customers as well employees, partners, and public) will interact with the system on their own terms, according to their expectations, via any channel, at any time, in any way they see fit. Today they may have more time, tomorrow less – and they would appreciate a quick summary today, and more information tomorrow. To accommodate these shifting expectations, each experience will be built ad-hoc by the stakeholder – provided they have access to all systems, information, and rules that apply.
This is the essence of being digital: building an infrastructure that allows any stakeholder to interact with any part of your organization, at any time, anyway they want, for anything they need. if you can do that, you are “living la vida digital”
To get there, that’s what you need to do over the next decade; this is not a simple system purchase and deployment. It requires extensive changes in all layers of the organization: people, process, and technology. It also requires new thinking in governance and metrics. and that — that takes a decade or so to complete.
Your move.
disclaimer: first things first, thanks to Jon Reed for the idea of using crossed-out text. Since Sameer Patel does not like my parenthetical digressions, I am testing some minor ones using crossed-out text to see if it works. if it does, all credit belongs to Jon who uses them to great effect (far greater than I could ever do) at Diginomica. I would reluctantly, but understandably, relinquish the use if he asks. second, I also have to give credit to the kind folks at OpenText who helped me with the first chart a bit during a consulting session in December. the other people, many, who contributed over time are also very kind and i am profoundly thankful – but they were more motivation and inspiration, OpenText tweaked the slide for me and let me use it. third, no vendors are mentioned – but y’all know that i work mostly with them, so there’s a chance that some of this stuff shows up in something they do / use and i will gladly take all the credit for that. ideas are mine, originally and follow-through, so feel free to yell at me for anything i got wrong. if it works, not me – if it didn’t, me. comment box is below. thanks for reading.













 Oscar was able to get 16,000 people to say yes to their plan selections and buying process in their first year.
Oscar was able to get 16,000 people to say yes to their plan selections and buying process in their first year.



