Digital Business Distributed Business and Technology Models Part 5; Business Apps and Services
Vice President and Principal Analyst, Constellation Research
Constellation Research
Andy Mulholland is Vice President and Principal Analyst focusing on cloud business models. Formerly the Global Chief Technology Officer for the Capgemini Group from 2001 to 2011, Mulholland successfully led the organization through a period of mass disruption. Mulholland brings this experience to Constellation’s clients seeking to understand how Digital Business models will be built and deployed in conjunction with existing IT systems.
Coverage Areas
Consumerization of IT & The New C-Suite: BYOD,
Internet of Things, IoT, technology and business use
Previous experience:
Mulholland co authored four major books that chronicled the change and its impact on Enterprises starting in 2006 with the well-recognised book ‘Mashup Corporations’ with Chris Thomas of Intel. This was followed in…...
Read more
The Digital Economy will consist of ecosystems participating in interactions from which multiple participants benefit. On route to this new market, most established Enterprises look to add Digital Technology to enhance their current Business model. However, unrecognized competitors in the form of startups are already establishing new Business ecosystems around Smart Services. This series started by defining a Digital Enterprise as an operating business in Part 1, and continued by exploring the technology frame work to deliver this in Parts 2,3a, 3b and 4. In this the concluding, Part 5, a real example is used to illustrate exactly how one, of the many, small startups is quietly creating a Digital Ecosystem around a new set of Smart Services in an established market.
IOTAS, a real company with the tag line ‘Smart Apartment made easy’, is creating a distributed Digital Business model integrating Landlords, Renters, Building Services, and Utility companies into a mutually beneficial Digital ecosystem. In the past all these participants had individual relationships operating in isolation, often under duress, when required by events. IOTAS ‘Smart Apartments’ proposition introduces a new Digital Business and Technology model built round an ecosystem.
Normally case studies on IoT and Digital Business feature established companies who have added Digital capabilities to extend their existing business model. The use of IOTAS as an example is to emphasis how well funded standups are quietly, often almost invisibly, creating new Digital Business models and business ecosystems. Many of these companies are not recognized as competitors simply because they don’t attack using the current business model, but instead look for the ‘white spaces’ between existing business models.
Some years ago in a Harvard Business Review article the following definition was used to describe the then popular term of White Space; “market opportunities your company may wish — or need — to pursue that it cannot address unless it develops a new business model.” Today this is definition absolutely fits these new market players’ moves.
To some Uber is seen as a one off exception to normal business exploiting a lucky fluke market condition, but as IOTAS and others demonstrate this is simply not true. By attacking the White Space between existing business models these new startup companies can build substantial positions before existing Enterprises even become aware of their presence as competitors or disruptors.
These new Digital Economy players aim to isolate the sales route to the existing market suppliers and introduce themselves as a market intermediary. This is not new; Amazon has been exploiting this strategy for many years, what has changed is consumer acceptance, plus the abilities of IoT coupled with AI over Clouds, Apps and Services to deliver. (The technologies of CAAST; Cloud, Apps, AI, Services & Things).
All successful established Enterprises should be monitoring at least three startups that are aiming to enter and disrupt some element of their market to increase their understanding of Digital Business models. It is easy to find these startups by the specialized listing companies that maintain records of Venture Capital investments and success rates.
IOTAS targets the rented apartment market in the USA, selling the capability to deploy ‘Smart Apartments’ as a commercial value proposition to Landlords as the buyer. The proposition creates an Digital Business ecosystem by providing clear value benefits to four different communities; Landlords, Renters, Building Maintenance and Utilities. IOTAS also takes advantage of a change in consumer attitudes to Lifestyle choices created by Digital Technology. The US rental market is continuously growing while home ownership rates have steadily fallen since a high in 2006. Ten years later in 2016 according to market research 13.6% of renters, approximately 5.5 million people, could afford to buy, but chose to rent to facilitate their lifestyle.
This shift is inline with similar behavior changes in other markets as the ‘Service’ economy grows around a new ‘Digital’ generation who has adopted new ‘flexible’ lifestyles. The ‘Digital Lifestyle” renter will pay a premium for an apartment that supports this lifestyle requiring not just a fast Internet connection and WiFi, but the additional lifestyle features of a Smart Apartment.
IOTAS provides Landlords with a complete package for each rental building that combines making individual apartments ‘smart’ for the renter with the increased operational benefits of a Smart Building for the Landlord. Renters gain the ability to ‘tailor’ the apartment facilities, plus gaining an IOTAS transportable profile that they can reassign to their next rental apartment. (Subject to their new landlord offering an IOTAS Smart Apartment deployment).
In addition to gaining a market differentiation plus premium pricing the Landlord also gains the advantages of reduced operating costs from using Smart Building management. IoT based sensing to improve proactive fault identification and automate maintenance responses, as well energy utilization control all increase the benefits.
The IOTAS approach brings Renters, Landlords, Building Maintenance Contractors and Utilities together in a Business Ecosystem, providing each with direct benefits from the relationship. It is important to recognize that existing traditional Business relationships to manage apartments and provide supporting services will be changed and new competitive pressures introduced.
The diagram below illustrates the four layers of the Framework developed in this series, but with the top layer illustrating the IOTAS Digital Ecosystem. (A summary of the four layers is provided at the end of this blog). There will be multiple ecosystems present and not all will be separate from each other, a building maintenance company could well be present in multiple ecosystems.
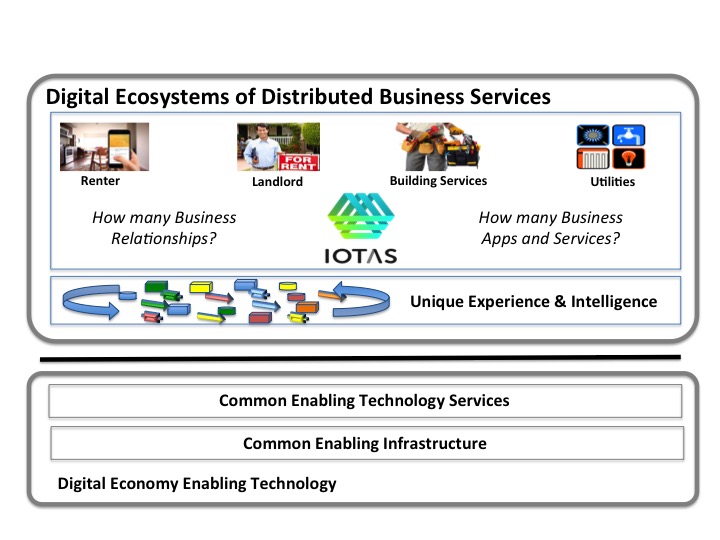
The obvious question is why start the definition of Business Apps and Services layer with Ecosystems? The answer lies in the difference between the Digital Economy and the Web Economy. The Digital Economy supports interactive ‘read’ and dynamic optimization of ‘respond’ to events, (consider Uber), amongst participating members of the ecosystem, (Taxi drivers, passengers, hotels, restaurants, etc.). In contrast an Enterprise Web site publishes static ‘forms’ to provide data entry into a constant and unchanging processing application.
A Smart Service, as opposed to a Web Service, achieves its interactive and responsive capability by orchestrating participants who have chosen to belong to its ecosystem. This is achieved both by its functionally valuable ‘Business’ Apps, and Services, as well as by its enabling ‘platform’ that provides both Technology Part 3a and Business Part 3b Distributed Services.
This leads to the question as to why different between an App, and a Service? In Business terms, as opposed to the more complex technology definitions, an App defines a Business function that is totally under the control of one Enterprise. A Service on the other hand is an orchestration of Business functions derived from multiple Enterprises and creates interdependencies. The IOTAS user App with IOTAS platform provides a Renter with Smart Apartment control in a closed bundled solution. To create a Smart Building requires the integration of products and online services from multiple vendors with the resulting interdependencies. The business benefits delivered are high for the Ecosystem integrator, as is the potential for improved customer relationships.
 The downloadable IOTAS Smart Phone App provides each renter with individual Smart Apartment management through the IOTAS Apartment Building Platform. IOTAS provides a fully functioning solution using its proprietary products, and is fully responsible and accountable for the reliable operation and maintenance of App. As is usually the case with Apps all, or a majority, of the Service revenues belong to IOTAS.
The downloadable IOTAS Smart Phone App provides each renter with individual Smart Apartment management through the IOTAS Apartment Building Platform. IOTAS provides a fully functioning solution using its proprietary products, and is fully responsible and accountable for the reliable operation and maintenance of App. As is usually the case with Apps all, or a majority, of the Service revenues belong to IOTAS.
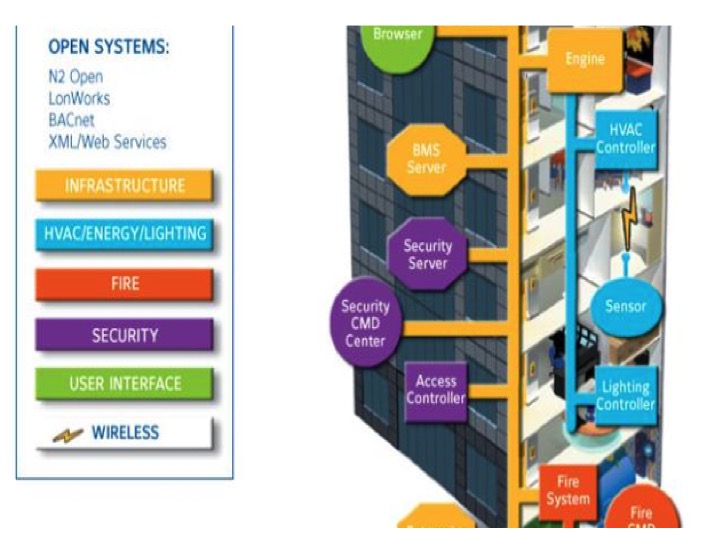
The IOTAS platform is a capability that can be integrated into the Smart Building deployment, alongside Building Infrastructure Management, (BIM), Utility Smart Meters, and other IoT sensed Services. The Business beneficiary of the Smart Building, (apartment block), is the landlord seeking to both reduce the cost of operating the building as well as improving the efficiently by integrating the ecosystem of providers.
Smart Building management represents a further level of Digital Business ecosystems and for this, and again a real example, Honeywell, a tradition market leader, provides an illustration. Increased use of IoT sensing, on board digital processing in products, such as Heating and Ventilation units, combined with intelligent building control systems have resulted in Smart Buildings becoming a recognized market place. Honeywell has moved to introduce new ‘intelligent’ versions of its products as well as adding an extension of its Business model to become a Smart Building ‘Integrator’ around its EBI 500 platform.
First mover Enterprises in a range of Industry sectors, (John Deere is often used as an example), have moved to create and control an ecosystem of smaller and more specialized suppliers. In the Smart Apartment block building Honeywell can become the ‘master’ building ecosystem provider making IOTAS a member of the Honeywell Smart Building ecosystem of partners.
App providers of unique, innovative, high value specialized business add to the business value of the overall Ecosystem of solutions. Those Enterprises that can become Ecosystem owners reinforce their current positions, extend their competitive value and differentiation, as well as gain new revenue sources from their ecosystem partners.
The sources, types and amounts of data produced by these ecosystems provides the game changing inputs to Augmented Intelligence capabilities outlined in Part 4, and summarized at the end of this blog. Continuous optimization of operations becomes possible to produce the Digital Enterprise as outlined in Part 1.
The two examples; IOTAS and Honeywell, were selected to illustrate the contrast between two different approaches that are creating Digital markets; IOTAS an innovative startup creating a Digital market and Ecosystem that has not previously existed through an App; and Honeywell an established vendor repositioning to become a Digital Marketplace of Services supported by an Ecosystem of both existing vendors plus startup vendors.
Though there are common elements with the second Digital Business models, there is a third model based purely on providing ‘Service Orchestration’. As with the first two there has to be an enabling product, a big part of the difference is that it is usually, but not always, as part of the enabling Distributed Services Technology or Business layers. These Enterprises aiming to satisfy a new and emerging market for Digital Services fall into four distinctive groups, and these are explored in the next blog entitled ‘Four IoT Business models’. Once again the defining feature, as with all Digital Market places, is the creation and operation of an Ecosystem.
The combination of the Digital representation of assets and events, with the interaction between members of an ecosystem, produces not just more data, but new, previously not available, new types of context. This provides both the input and the demand for a very different form of output, both in time frames and in ability to be turned into optimized reactions. The capabilities and role of Intelligence leading into Augmented Intelligence or AI is outlined in Part 4.
The coupling between the Business Apps, and Services, with the use of Augmented Intelligence is the focal point that technology vendors are targeting, and will be the driving force for new levels of Enterprise competitive operation of their own Business, as much as those of the Digital Market place. See The Digital Enterprise Business model defined in Part 1 of this series.
Summary; Background to this series
This is third part in a series on Digital Business and the Technology required to support the ability of an Enterprise to do Digital Business. An explanation for the adoption of a simple definition shown in the diagram below to classify the technology requirements rather than attempt any form of conventional detailed Architecture is provided, together with a fuller explanation of the Business requirements.

Part One - Digital Business Distributed Business and Technology Models;
Understanding the Business Operating Model
Part Two - Digital Business Distributed Business and Technology Models;
The Dynamic Infrastructure
Part Three – Digital Business Distributed Business and Technology Models
- Distributed Services Technology Management Distributed Services Business Management
Part Four – Digital Business Distributed Business and Technology Models
Augmented Intelligence and Machine Learning
New C-Suite
Data to Decisions
Future of Work
Innovation & Product-led Growth
Tech Optimization
AI
ML
Machine Learning
LLMs
Agentic AI
Generative AI
Analytics
Automation
B2B
B2C
CX
EX
Employee Experience
HR
HCM
business
Marketing
SaaS
PaaS
IaaS
Supply Chain
Growth
Cloud
Digital Transformation
Disruptive Technology
eCommerce
Enterprise IT
Enterprise Acceleration
Enterprise Software
Next Gen Apps
IoT
Blockchain
CRM
ERP
Leadership
finance
Customer Service
Content Management
Collaboration
M&A
Enterprise Service
Chief Information Officer
Chief Technology Officer
Chief Digital Officer
Chief Data Officer
Chief Analytics Officer
Chief Information Security Officer
Chief Executive Officer
Chief Operating Officer