DeepSeek's paper latest evidence AI muscle head era coming to end
DeepSeek published a technical paper co-authored by co-founder Liang Wenfeng that argues for a new architecture to train foundational models.
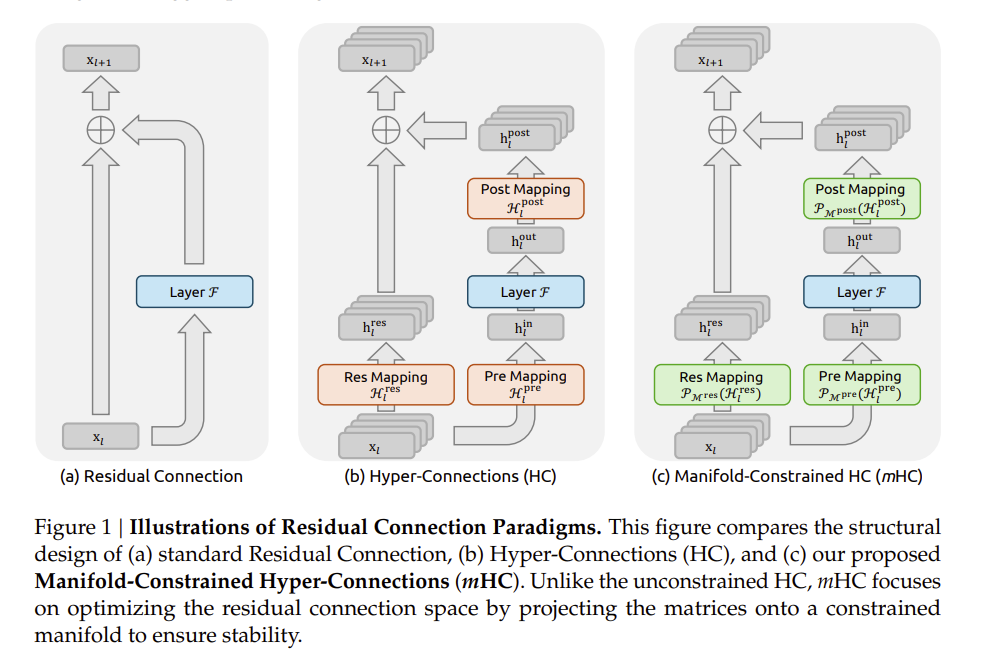
The paper, which details Manifold-Constrained Hyper-Connections (mHC), argues that a new architecture is needed to better scale deep learning without signal divergence. Granted, the mHC paper is wonky, but the key takeaway is that you can have large-scale training that's more efficient with better quality.
"Empirical results confirm that mHC effectively restores the identity mapping property, enabling stable large-scale training with superior scalability compared to conventional HC. Crucially, through efficient infrastructure-level optimizations, mHC delivers these improvements with negligible computational overhead."
Given that DeepSeek's paper landed the day after New Year's Day, it's unlikely to garner a ton of attention. However, DeepSeek's paper is just another development leading to the following: The muscle head era (error) of AI is coming to an end.
The AI market to date has been driven by muscle head logic. The answer for everything in the last two years has been more muscle. In AI's case that approach means more GPUs, more farm land going away, more energy usage, more water and by all means more data centers, debt and capital expenditures.
Almost a year ago, DeepSeek's LLM rattled the AI market because it appeared to be more efficient and trained without the latest and greatest from Nvidia. After an early freakout over DeepSeek, the US-driven part of the AI market went right back to the Stargate happy approach. Toward the end of 2025, investors were starting to question the capital expense and debt load behind the AI buildout.
In 2026, we're likely to see more engineering excellence and less muscle head logic. Here's some evidence to why that theory may play out.
- Price and performance matter. LLM giants were busy diversifying their chip bases. Google's TPUs and Amazon Web Services' Trainium are going to be threats to Nvidia as inference becomes the main event.
- Capital expenditures and debt loads are being questioned. Just ask Oracle and Meta.
- Nvidia's not acquisition of Groq. Nvidia licensed Groq and hired damn near the whole company away because Groq's approach to memory and inference is more cost effective.
- NIMBY is brewing. Yes, tech titans would pave over every inch of land for an AI factory, but you need power. Communities are going to become wary of paying higher electric bills for AI. Sen. Bernie Sanders of Vermont and Florida Gov. Ron DeSantis agree on little, but both agree AI's data center boom is a raw deal.
- China is pushing new architectures that are easy on compute. The US has deprived China of Nvidia's best chips (until recently). As a result, China has eyed more efficient training and embraced open source. DeepSeek has the incentive to push new AI architectures. The US is more muscle over elegance.
DeepSeek's real legacy: Shifting the AI conversation to returns, value, edge | China vs. US AI war: Fact, fiction or missing the point?
These developments mean you can't just see DeepSeek's paper in a vacuum. It's just one more piece of evidence that AI is going to become way more efficient and that potentially means less compute.
Larry Dignan is Editor in Chief of Constellation Insights at Constellation Research, where he leads editorial coverage focused on enterprise technology, digital transformation, and emerging trends shaping the future of business. He oversees research-driven news, analysis, interviews, and event coverage designed to help technology buyers and vendors navigate complex markets with clarity and context. ...
Read morePublished
Author
