
Microsoft CEO Satya Nadella on Monday announced the next major release of the company’s flagship database management system, Microsoft SQL Server 2016. It's a significant milestone for a product has grown into a $5-billion-per-year business for Microsoft, second only to Oracle Database in revenue.
Introduced at this week’s Ignite Conference in Chicago, the new database will be released as a public preview this summer. As the name suggests, Microsoft SQL Server 2016 won’t see general availability until next year, but Microsoft offered plenty of feature tidbits to stoke anticipation. Here are a few highlights:
Stretch Database: A tie to the Microsoft Azure that lets you push warm database data or cold data into the cloud. Think cloud- or mobile-integrated apps with warm data or archiving of cold data.
In-memory enhancements: Last year Microsoft introduced in-memory OLTP for transactional application performance improvements. SQL Server 2016 will deliver in-memory analytics.
In-database analytics: The headline here is R integration, which certainly isn’t new in the industry. But given Microsoft’s recent Revolution Analytics acquisition, the company could do give Oracle and Teradata stiffer in-database analytics competition.
Always Encrypted. This feature will please the security crowd, as it will protect data at rest and in motion.
Diving deeper, the Stretch Database feature is about supporting hybrid scenarios. For example, as transactional tables grow in size, Stretch gives you a way to archive historical (cold) data. This reduced the size and cost of the core database deployment while maintaining fast performance. In a different hybrid scenario, operational (warm) data could be “stretched” to Azure to bring fresh data to a cloud- and/or mobile-integrated app.
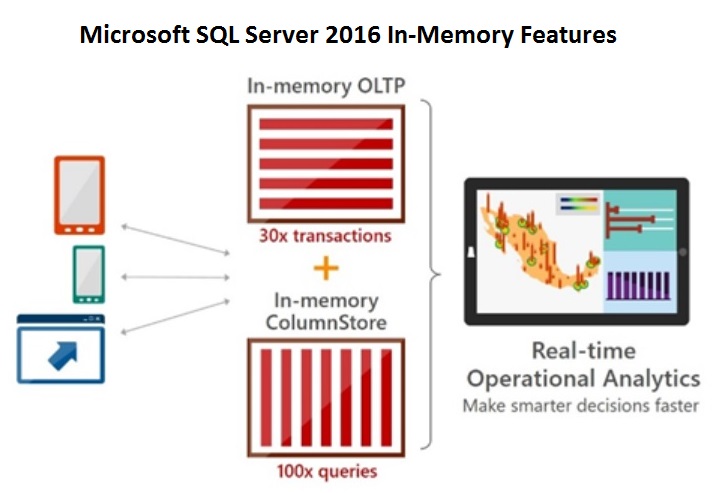
In-Memory Analytics
Oracle promises both analytical and transactional performance gains through the Oracle In-Memory Database option introduced last year. Microsoft introduced in-memory analytics with its in-memory columnstore with SQL Server 2012. If focused purely on transaction processing gains with its In-Memory OLTP option for SQL Server 2014. With SQL Server 2016, Microsoft says in-memory columnstore enhancements will deliver up to 100X faster query performance for “real-time” operational analytics by running on data that is already benefitting from in-memory OLTP. This is a step up on the analytical side where Microsoft needed to show more in-memory performance improvement.
This in-memory option will become even more important when it’s made available as part of the Azure SQL Data Warehouse service announced last week at Microsoft’s Build Conference (see Holger Mueller’s complete coverage). This Azure cloud-based version of Microsoft SQL Server Parallel Data Warehouse, due as a preview in June, will compete with Amazon Redshift and other followers in that category including IBM DashDB and HP Vertica OnDemand. All are columnar databases that can take advantage of memory, but I suspect Microsoft’s in-memory option could give it better memory capacity and control.
Of course, SAP has been touting both transactional and analytic performance benefits for years because its Hana platform is entirely in memory. The Oracle and Microsoft features are just that – add-ons to conventional databases that rely mostly on disk-based storage. The upside with this approach is that existing applications don’t have to be rebuilt to run on the new database. To take advantage of the in-memory feature (which is an extra-cost option on Oracle versus a build-in feature of Microsoft SQL Server), you use administrative features to place selected indexes in memory or to query against in-memory columns.
Built-in Advanced Analytics
For years now, data scientists have been pushing advanced analytic workloads into databases because they offer much more processing horsepower than dedicated analytic servers. What’s more, you save time because you don’t have to move data to a separate server for computation and then move result sets back to a data warehouse. The idea is to bring the analytics to the data instead of the other way around.
So in-database analysis is nothing new, but given that Microsoft now owns Revolution Analytics, it only makes sense to make the most of this vendor’s curated portfolio of R-language-based analytics into SQL Server. Revolution has had an in-database alliance in place with Teradata since 2013, and Microsoft says that's not going away in the wake of the acquisition.
Microsoft will also build the Hadoop-access-tool PolyBase into SQL Server 2016, so you’ll be able to access unstructured data from Hadoop as well structured data within the database using T-SQL skills. Teradata and Oracle also offer Hadoop-data-access options, so we’ll need to see more details on the advantages of having PolyBase built into the database to understand just how it stands out.
First Take: Evolutionary, Not Revolutionary
All of these moves make sense, but they’re not industry firsts. Teradata has had the ability to move hot and cold data to speed- and cost-appropriate storage options for years. The novel twist with Stretch is that it’s moving data into the cloud. If it’s easy, or better still, automated, it could power novel hybrid apps, performance gains and real database license savings. We’ll see if Oracle tries to match a feature that could diminish database revenue.
The in-memory and in-database analytics features and Hadoop data access promised in SQL Server 2016 look like they’ll deliver state-of-the-industry rather than state-of-the-art capabilities. But these aren’t the only new features in store for the new database. Microsoft is also promising row-level security and dynamic data masking, native JSON support, faster backups, high-availability improvements and more. I’ll reserve final judgement until Microsoft takes the wraps off the preview release later this summer.